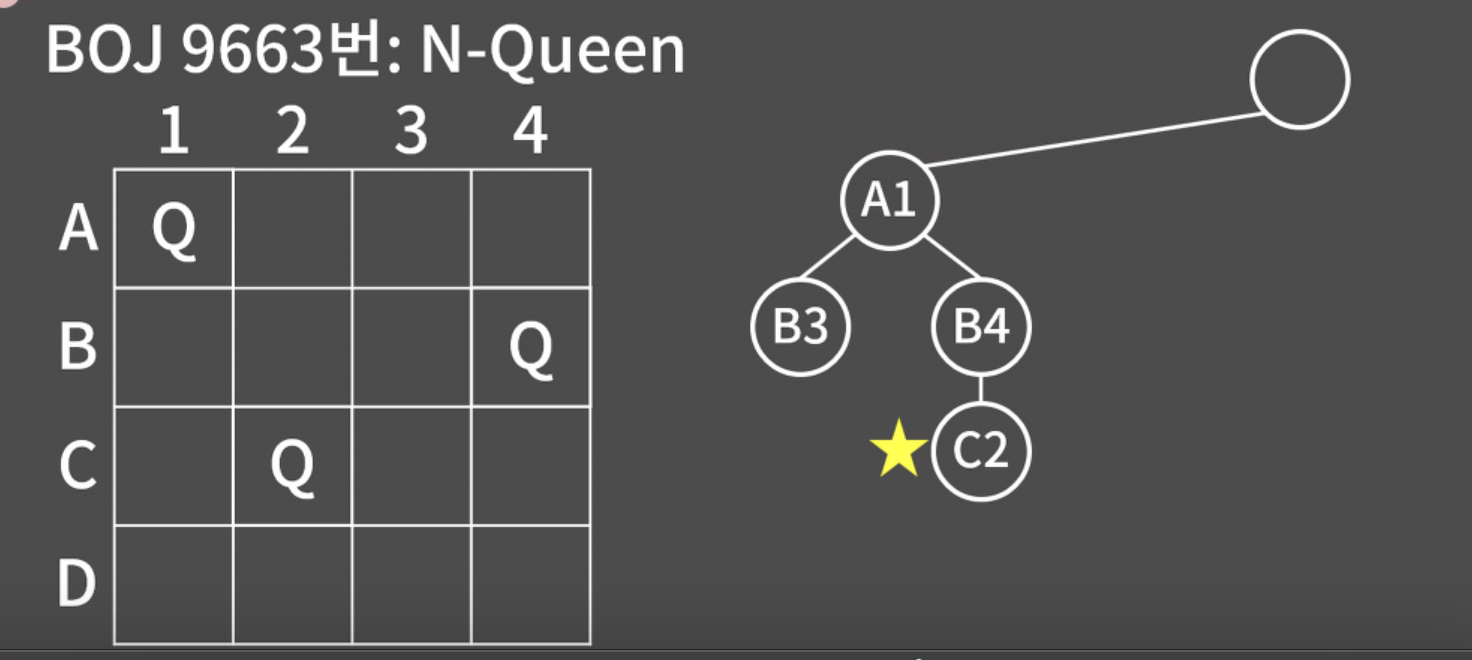
두 원소의 우선순위가 같다면 원소의 위치를 변경하지 않는다. 사용법은 sort()와 똑같다.
[중요] 비교 함수
sort() 함수의 파라미터로 비교함수를 넘길 수 있다. stable_sort()도 마찬가지다.
예를 들어, int형을 5로 나눈 나머지 순으로, 5로 나눈 나머지가 같다면 크기 순으로 정렬하고 싶으면 아래 코드처럼 하면 된다.
비교함수 cmp는 a가 b의 앞에 와야할 때 true를, 그렇지 않을 때 false를 반환한다.
bool cmp(int a, int b){ // a가 b의 앞에 와야할 때 true, 아니면 false
if(a % 5 != b % 5) return a % 5 < b % 5;
else a < b;
}
int a[7] = {1, 2, 3, 4, 5, 6, 7};
sort(a, a+7, cmp);
// 출력 결과: 5 1 6 2 7 3 4
비교함수 구현 시 자주하는 실수
1. a가 b의 앞에 와야할 때만 true를 반환한다. a==b 라면 false를 반환한다.
예를 들어, 수열을 크기의 내림차순으로 정렬하고 싶을 때, a와 b가 같은 경우 false를 반환하니까 런타임 에러가 발생할 수 있다.
bool cmp(int a, int b){ // [런타임 에러 발생]
if(a >= b) return true;
return false;
}
a > b 일 때 true를 반환하도록 수정하자.
bool cmp(int a, int b){ // 올바른 형태
return a > b;
}
2. 비교 함수의 인자로 STL 혹은 클래스 객체를 전달시 reference를 사용하자.
문자열을 받아서 끝자리의 알파벳 순으로 정렬하고 싶어서 비교함수를 작성했다.
아래의 비교함수는 어떻게 개선하면 좋을까?
bool cmp(string a, string b){
return a.back() < b.back();
}
// 함수의 인자로 STL이나 구조체 객체를 보내면 값의 '복사'가 일어난다!
함수의 인자로 STL이나 구조체 객체를 보내면 값의 '복사'가 일어남을 기억하자!
이 경우, 굳이 복사라는 불필요한 연산이 없어도 비교가 가능하다.
따라서 복사를 하는 대신 아래처럼 reference를 보내는 것이 더 바람직하다.
bool cmp(const string& a, const string& b){ // 레퍼런스를 보내서 비교하는 것이 효율적.
return a.back() < b.back();
}
const string& a, const string& b라고 쓰면 a와 b는 변하지 않음을 명시적으로 나타내기 때문에 가독성이 도움이 된다.
// http://boj.kr/f3feaf22016f4c9687b84ab6be2f4389
#include <bits/stdc++.h>
using namespace std;
int n;
long long a[100005];
int main(void) {
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n;
for(int i = 0; i < n; i++)
cin >> a[i];
sort(a, a+n);
int cnt = 0;
long long mxval = -(1ll << 62) - 1; // 1을 long long으로 형변환하지 않고 1 << 62로 작성시 int overflow 발생
int mxcnt = 0;
for(int i = 0; i < n; i++){
if(i == 0 || a[i-1] == a[i]) cnt++; // i가 0인 경우 앞쪽 식이 true이기 때문에 a[i-1]을 참조하지 않음
else{
if(cnt > mxcnt){
mxcnt = cnt;
mxval = a[i-1];
}
cnt = 1;
}
}
if(cnt > mxcnt) mxval = a[n-1]; // 제일 마지막 수가 몇 번 등장했는지를 별도로 확인
cout << mxval;
}
코드 마지막 줄에 '제일 마지막 수가 몇 번 등장했는지 별도로 확인'해야 한다.
이 처리가 빠지면 제일 마지막 수의 등장 횟수를 빠뜨리게 된다.
이 문제에서 사용한 정렬을 하면, 같은 수는 인접하게 된다는 성질을 이용해 수열에서 중복된 원소를 제거할 수 도 있다.
그 다음 큰 것을 찾아서 뒤로 보낸다 ... 이렇게 이어질 테니 계산해보면 시간복잡도는 O(N^2) 이다.
선택정렬 코드
int arr[10] = {3, 2, 7, 116, 62, 235, 1, 23, 55, 77};
int n = 10;
for(int i = n-1; i > 0; i--){ // 최대값을 찾으면 i위치로 보낼것이다. i:맨 마지막부터 앞에서 두번째 까지.
int mxidx = 0;
for(int j = 1; j <= i; j++){
if(arr[mxidx] < arr[j]) mxidx = j;
}
swap(arr[mxidx], arr[i]);
}
선택 정렬은 가장 큰 수를 찾으면, 인덱스 i로 이동시킨다. 내부 반복문에서 mxidx 인덱스와 j인덱스 자리의 숫자를 비교한다. 이 반복문이 종료되면 가장 큰 숫자의 인덱스가 mxidx에 저장된다. 가장 큰 숫자 인덱스 mxidx와 뒤쪽 인덱스 i를 swap한다. ( == 가장 큰 숫자를 뒤로 보낸다)
max_element 함수로 줄여본 코드
max_element(arr, arr+k)
// arr[0], arr[1], arr[2], .. , arr[k-1] 에서 최댓값인 원소의 주소를 반환
arr[0]부터 arr[k-1] 까지 탐색한 후 최댓값인 원소 주소를 반환한다.
arr[k]가 아니라 arr[k-1]임을 주의하자.
int arr[10] = {3, 2, 7, 116, 62, 235, 1, 23, 55, 77};
int n = 10;
for(int i = n-1; i > 0; i--){ // 맨 마지막부터 앞에서 두번째 까지.
swap(*max_element(arr, arr+i+1), arr[i]);
}
#include <bits/stdc++.h>
using namespace std;
int n = 10;
int arr[1000001] = {15, 25, 22, 357, 16, 23, -53, 12, 46, 3};
int tmp[1000001]; // merge 함수에서 리스트 2개를 합친 결과를 임시로 저장하고 있을 변수
// mid = (st+en)/2라고 할 때 arr[st:mid], arr[mid:en]은 이미 정렬이 되어있는 상태일 때 arr[st:mid]와 arr[mid:en]을 합친다.
void merge(int st, int en){
int mid = (st+en)/2;
int lidx = st; // arr[st:mid]에서 값을 보기 위해 사용하는 index
int ridx = mid; // arr[mid:en]에서 값을 보기 위해 사용하는 index
for(int i = st; i < en; i++){
if(ridx == en) tmp[i] = arr[lidx++];
else if(lidx == mid) tmp[i] = arr[ridx++];
else if(arr[lidx] <= arr[ridx]) tmp[i] = arr[lidx++];
else tmp[i] = arr[ridx++];
}
for(int i = st; i < en; i++) arr[i] = tmp[i]; // tmp에 임시저장해둔 값을 a로 다시 옮김
}
// a[st:en]을 정렬하고 싶다.
void merge_sort(int st, int en){
if(en == st+1) return; // 리스트의 길이가 1인 경우
int mid = (st+en)/2;
merge_sort(st, mid); // arr[st:mid]을 정렬한다.
merge_sort(mid, en); // arr[mid:en]을 정렬한다.
merge(st, en); // arr[st:mid]와 arr[mid:en]을 합친다.
}
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
merge_sort(0, n);
for(int i = 0; i < n; i++) cout << arr[i] << ' '; // -53 3 12 15 16 22 23 25 46 357
}
merge함수에서 두 리스트를 합친 결과를 임시롤 저장할 곳이 필요해서 tmp 변수가 필요하다.
merge_sort함수에서 배열의 크기가 1일 때는 아무것도 안해도 정렬이 완료된다.
이후에는 재귀적으로 절반을 나눠 각각 정렬이 되게 한다.
아직 헷갈리더라도 이건 어려운 내용인것이 맞고 시간과 반복시도가 해결해주는 문제니까 계속 가면 된다.
만약 l 과 r이 타겟을 못찾으면 l > r 이 된다. 인덱스 l과 r이 역전되버린다. 이 때는 break 로 탐색을 멈춘다.
l 과 r이 타겟을 찾으면, swap(arr[l], arr[r]) 스왑 한다!
스왑이 종료되면, 인덱스 r과 인덱스 pivot을 스왑한다.
그리고 pivot을 기준으로 왼쪽과 오른쪽을 보면 pivot이 올바른 자리에 있음을 확인할 수 있다.
나머지 부분은 재귀호출해서 정렬시킨다.
#include <bits/stdc++.h>
using namespace std;
int n = 10;
int arr[1000001] = {15, 25, 22, 357, 16, 23, -53, 12, 46, 3};
void quick_sort(int st, int en) { // arr[st to en-1]을 정렬할 예정
if(en <= st+1) return; // 수열의 길이가 1 이하이면 함수 종료.(base condition)
int pivot = arr[st]; // 제일 앞의 것을 pivot으로 잡는다. 임의의 값을 잡고 arr[st]와 swap해도 상관없음.
int l = st+1; // 포인터 l
int r = en-1; // 포인터 r
while(1){
while(l <= r && arr[l] <= pivot) l++;
while(l <= r && arr[r] >= pivot) r--;
if(l > r) break; // l과 r이 역전되는 그 즉시 탈출
swap(arr[l], arr[r]);
}
swap(arr[st], arr[r]);
quick_sort(st, r);
quick_sort(r+1, en);
}
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
quick_sort(0, n);
for(int i = 0; i < n; i++) cout << arr[i] << ' ';
}
3. 퀵 소트의 시간복잡도
pivot 하나를 올바른 자리에 보낼 때 마다 상수번의 연산으로 l과 r이 한 칸씩 가까워진다.
따라서한 세트의 시간복잡도는 O(N)이다.
재귀 종료 조건인 base condition은 구간의 길이가 1 이하일 때다. pivot을 제자리로 보낸 뒤에, 재귀적으로 자기 자신을 호출한다.
pivot 하나를 올바른 자리에 보내는 세트가 O(N)이 걸리는데.
pivot 을 하나씩 제외하면 N, N-1, N-2 ... 번의 연산이 필요하다.
4. 퀵 소트의 단점?
만약 pivot이 매번 완벽하게 중앙에 위치한다면?
리스트를 균등하게 반으로 쪼개서재귀를 호출하게 된다.
이 때는 n, n/2, n/4 ... 번의 연산이 필요할 것이다. 그러면 머지 소트때와 같이 세트마다 O(logN)이 걸린다.
한 세트의 연산횟수 N과 재귀 호출 연산횟수 logN을 곱하면 된다.
물론 항상 pivot이 완벽하게 중앙에 오지 않겠지만대략 시간복잡도는 O(NlogN)이 된다.
그리고 앞서 말한 cache hit rate가 높아서 퀵 소트는 속도가 굉장히 빠르다.
{1,2,3,4,5,6,7,8} 을 퀵 소트로 정렬하면 시간 복잡도가 얼마일까?
pivot은 항상 중앙에 있는게 아니라. 제일 왼쪽에 위치하게 된다.
그래서 한 단계마다 longN개가 아니라 N개를 확인해야 한다. -> 시간복잡도는 O(N^2)이 된다.
퀵 소트는 평균적으로 O(NlogN)이지만 최악의 경우 O(N^2)이다.
단순히 제일 왼쪽 값을 pivot으로 선택해보면 지금처럼 리스트가 오름차순 이거나 내림차순일 때 O(N^2)이 된다.
[참고]
STL을 못 쓰는 경우, 정렬을 직접 구현해야 한다면 퀵 소트를 쓰는게 아니라 머지 소트를 구현하라고 한 이유가 여기에 있다.
최악의 경우 O(N^2)의 시간복잡도인 퀵 소트를 쓸 필요가 없다.
하지만 대부분의 정렬 라이브러리는 퀵 소트를 쓰는 것도 사실이다.
pivot을 '잘'고르는 것이 관건인데. 랜덤으로 선택하거나. 후보 3개를 정해서 중앙값을 선택하기도 한다.
최악의 경우에도 O(NlogN)을 보장하기 위해 일정 깊이 이상의 재귀가 호출되면 힙 소트로 정렬한다.
재귀가 과도하게 호출되면 오버헤드 때문에 성능저하가 오는 데 이를 피하기 위함이다. 이러한 정렬을 Introspective sort라고 한다.
5. 머지 소트 VS 퀵 소트
머지소트와 퀵 소트는 둘 다 재귀적 구조로 구현된다.
먼저 시간복잡도를 보면 머지소트는 무조건 O(NlogN)이고. 퀵 소트는 최악에 O(N^2), 평균적으로 O(NlogN)이다.
평균적으로 (이름값하는) 퀵 소트가 빠르다.
퀵 소트는 In-Place Sort 인 점을 기억하자.
그리고 머지 소트는 우선 순위가 같은 원소들끼리의 원래 순서가 유지되는 Stable Sort이지만 퀵 소트는 아니다.
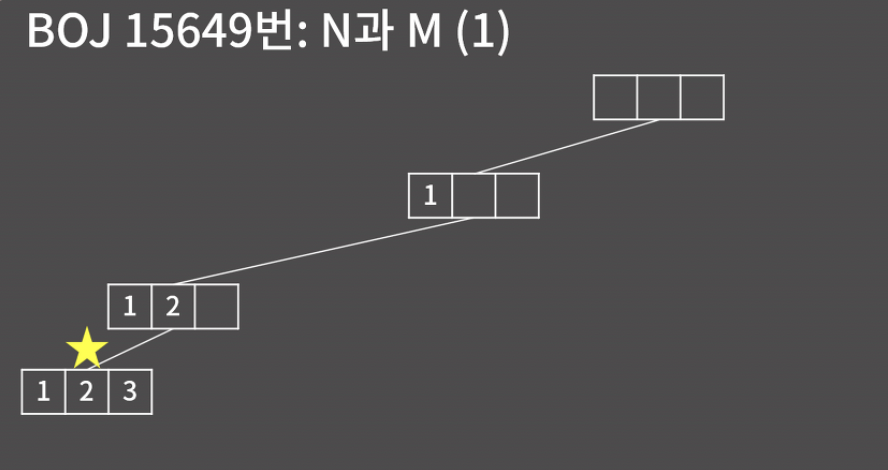
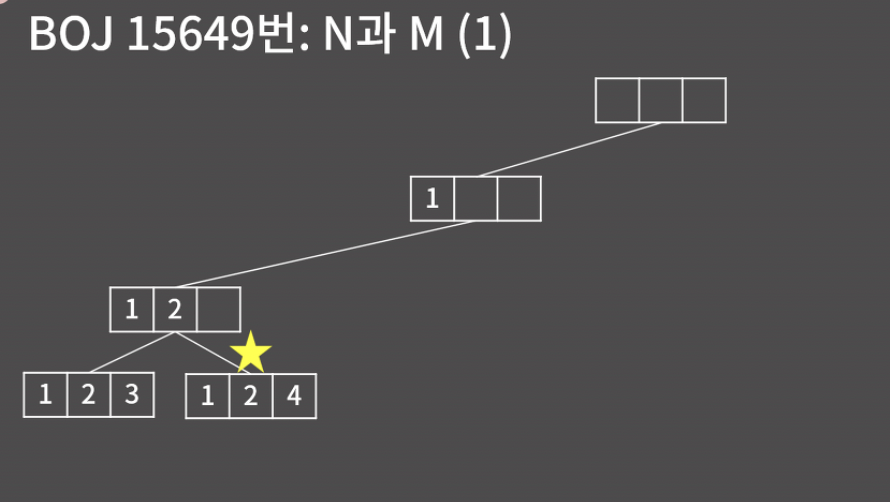
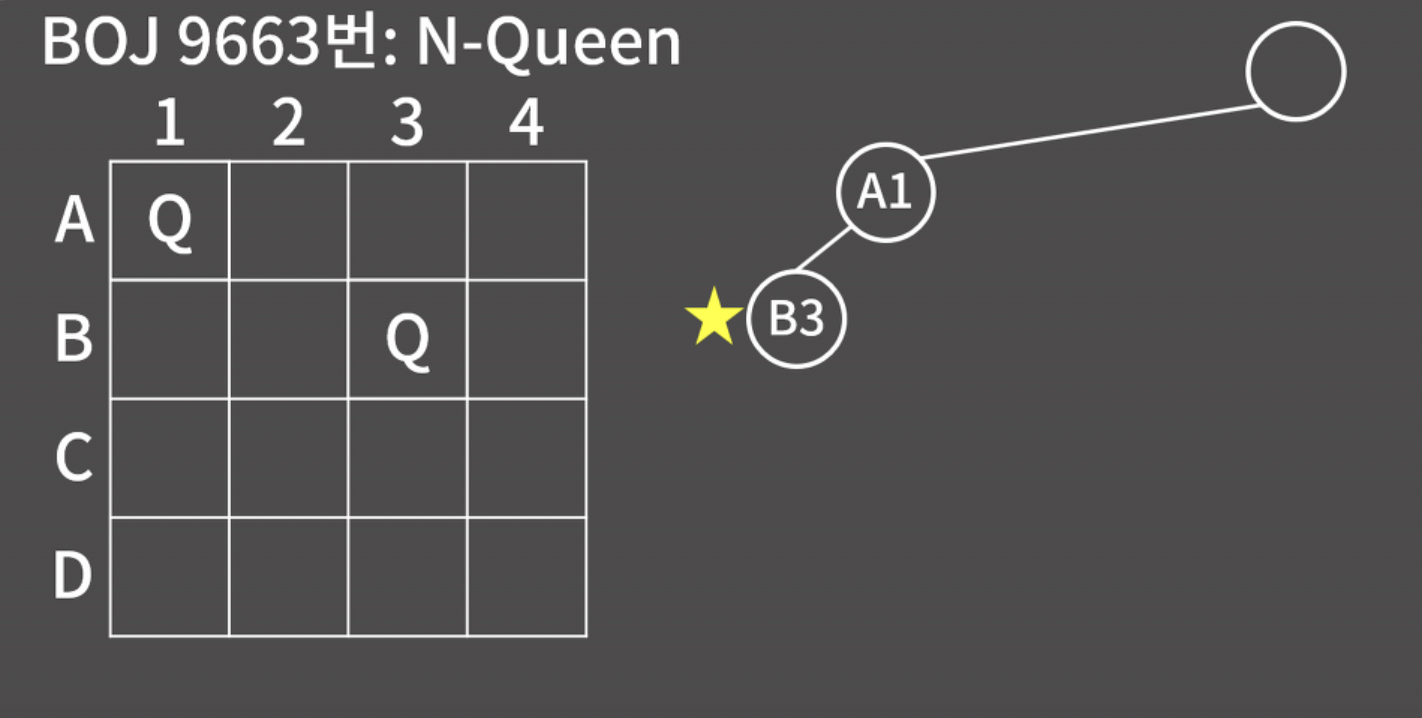
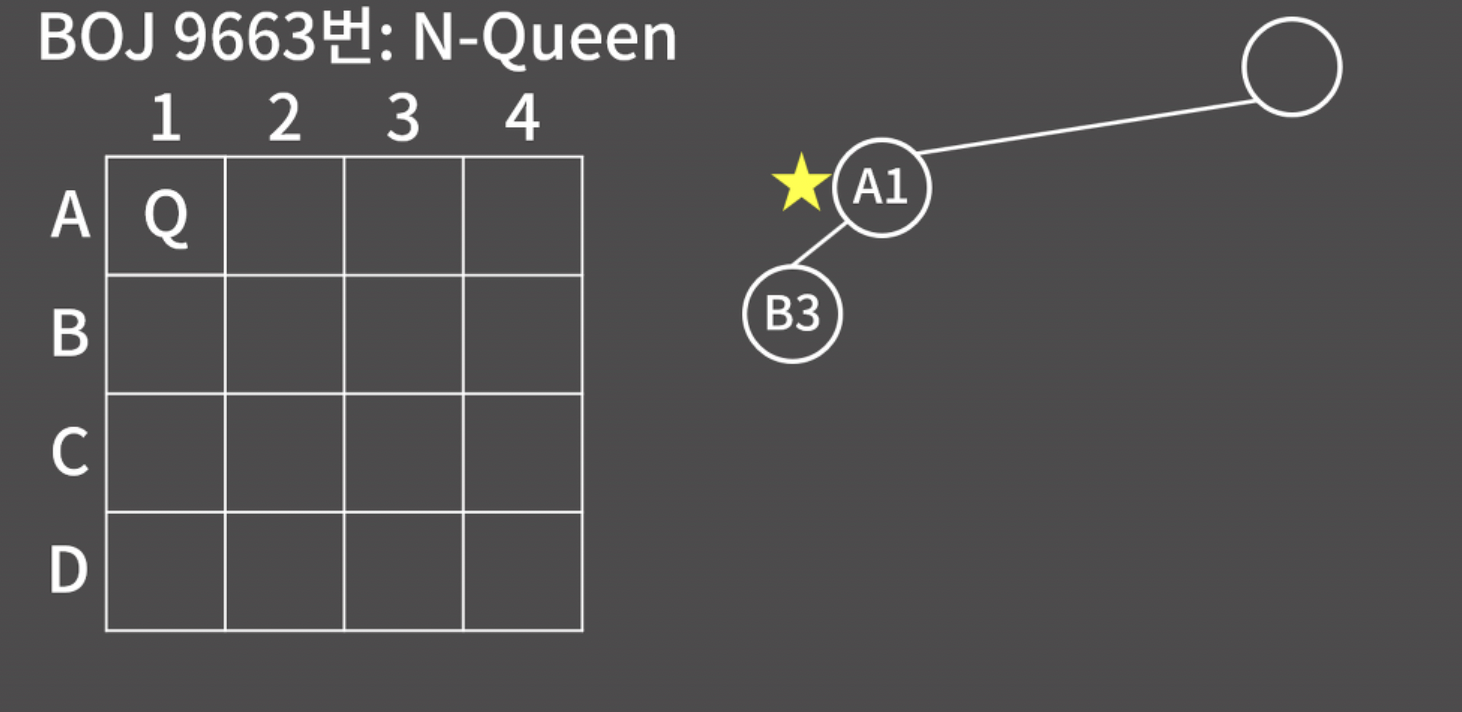
코드를 읽어 보면 재귀적으로 구현됬다. 이 모양은 백트래킹의 전형적인 구조니까 주석을 읽고 잘 익혀두자.
선택한 숫자를 저장하는 int arr 배열 1부터 n까지의 숫자 중에서 '선택 여부'를 저장하는 bool isused 배열 현재 몇 개의 숫자를 선택했는지 인자를 넘기는 재귀 함수 void func(int k ) 재귀 함수의 종료 조건(base condition)은 k가 m개를 모두 선택했을 때 이다.
// http://boj.kr/f36567ec0c9f44b4b460b5b29683c27b
#include <bits/stdc++.h>
using namespace std;
int n,m;
int arr[10];
bool isused[10];
void func(int k){ // 현재 k개까지 수를 택했음.
if(k == m){ // m개를 모두 택했으면
for(int i = 0; i < m; i++)
cout << arr[i] << ' '; // arr에 기록해둔 수를 출력
cout << '\n';
return;
}
for(int i = 1; i <= n; i++){ // 1부터 n까지의 수에 대해
if(!isused[i]){ // 아직 i가 사용되지 않았으면
arr[k] = i; // k번째 수를 i로 정함
isused[i] = 1; // i를 사용되었다고 표시
func(k+1); // 다음 수를 정하러 한 단계 더 들어감. 재귀 호출이므로 새로운 스택프레임 생성됨.
isused[i] = 0; // k번째 수를 i로 정한 모든 경우에 대해 다 확인했으니 i를 이제 사용되지않았다고 명시함.
}
}
}
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n >> m;
func(0);
}
func함수의 for문이 핵심이다.
1부터 n까지의 수에 대해 아직 i가 사용되지 않았으면 다음 수를 정하러 한 단계 더 들어간다.
for(int i = 1; i <= n; i++){ // 1부터 n까지의 수에 대해
if(!isused[i]){ // 아직 i가 사용되지 않았으면
arr[k] = i; // k번째 수를 i로 정함
isused[i] = 1; // i를 사용되었다고 표시
func(k+1); // 다음 수를 정하러 한 단계 더 들어감
isused[i] = 0; // k번째 수를 i로 정한 모든 경우에 대해 다 확인했으니 i를 이제 사용되지않았다고 명시함.
}
}
재귀로 다음 수를 정하러 함수를 호출하고 나서 종료되면, 현재 선택했던 수를 사용하지 않았다고 표시한다.
즉, 이전 단계로 돌아오는 것이다.
단 현재 값이 i인 arr[k]는 굳이 0과 같은 값으로 변경할 필요가 없다. 어차피 자연스럽게 다른 값으로 덮힐 예정이기 때문이다.
잘 모르겠다면 함수의 중간 중간 arr, isused, k를 출력한다던가 하는 방식으로 확인하고, (영상으로도 확인)
12의 58승을 67로 나눈 나머지가 4라면, 12의 116승을 67로 나눈 나머지는 (4의 제곱) 즉, 16이 된다.
-> 58승을 계산할 수 있으면 116승을 계산할 수 있다.
-> k승을 계산할 수 있으면 2k승과 2k+1승도 O(1)에 계산할 수 있다.
이 두 문장은 참이다. 따라서 a의 임의의 지수승을 귀납적으로 계산할 수 있다.
귀납법의 일부를 코드로 바꿔보자.
func(a, b, c)는 func(a, b/2, c)를 기반으로 구할 수 있다.
using ll = long long;
ll func(ll a, ll b, ll c){
val = func(a, b/2, c);
val = val * a % c; // a를 곱하고 c로 나눈 나머지
}
// func(a, b, c)는 func(a, b/2, c)를 기반으로 구할 수 있다.
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
ll A, B, C;
ll rec(ll a, ll b, ll c){
if(b == 1) return a % c; // a가 c보다 클 수 있기 때문에 a % c를 반환.
ll val = rec(a, b/2, c);
val = val * val % c;
if(b%2 == 0) return val;
return val * a % c; // b가 홀수라면 *a %c 를 한 번 더 수행.
}
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> A >> B >> C;
cout << rec(A, B, C);
return 0;
}
// http://boj.kr/9c320eecca4b4958bd54977f83371a36
이 함수의 시간 복잡도는 b가 계속 절반씩 깎이니까 O(log b)이다.
그래서 문제의 시간 제한을 넉넉히 지킬 수 있다.
0x02 연습문제2 - 하노이 탑
두 번째 문제는 재귀 문제 중에 스테디셀러인 하노이탑 문제다.
온라인 게임으로 원판 3, 4, 5개일 때를 깨고 오자. 하노이탑 문제가 뭔지 감이 올 것이다.
//바킹독님코드 http://boj.kr/f2440915dca04aaa9aec759080516973
#include <bits/stdc++.h>
using namespace std;
void func(int a, int b, int n){
if(n == 1){
cout << a << ' ' << b << '\n';
return;
}
func(a, 6-a-b, n-1);
cout << a << ' ' << b << '\n';
func(6-a-b, b, n-1);
}
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
int k;
cin >> k;
cout << (1<<k) - 1 << '\n'; // (1<<k)는 2의 k승이다.
func(1, 3, k);
}
0x03 연습문제3 - Z
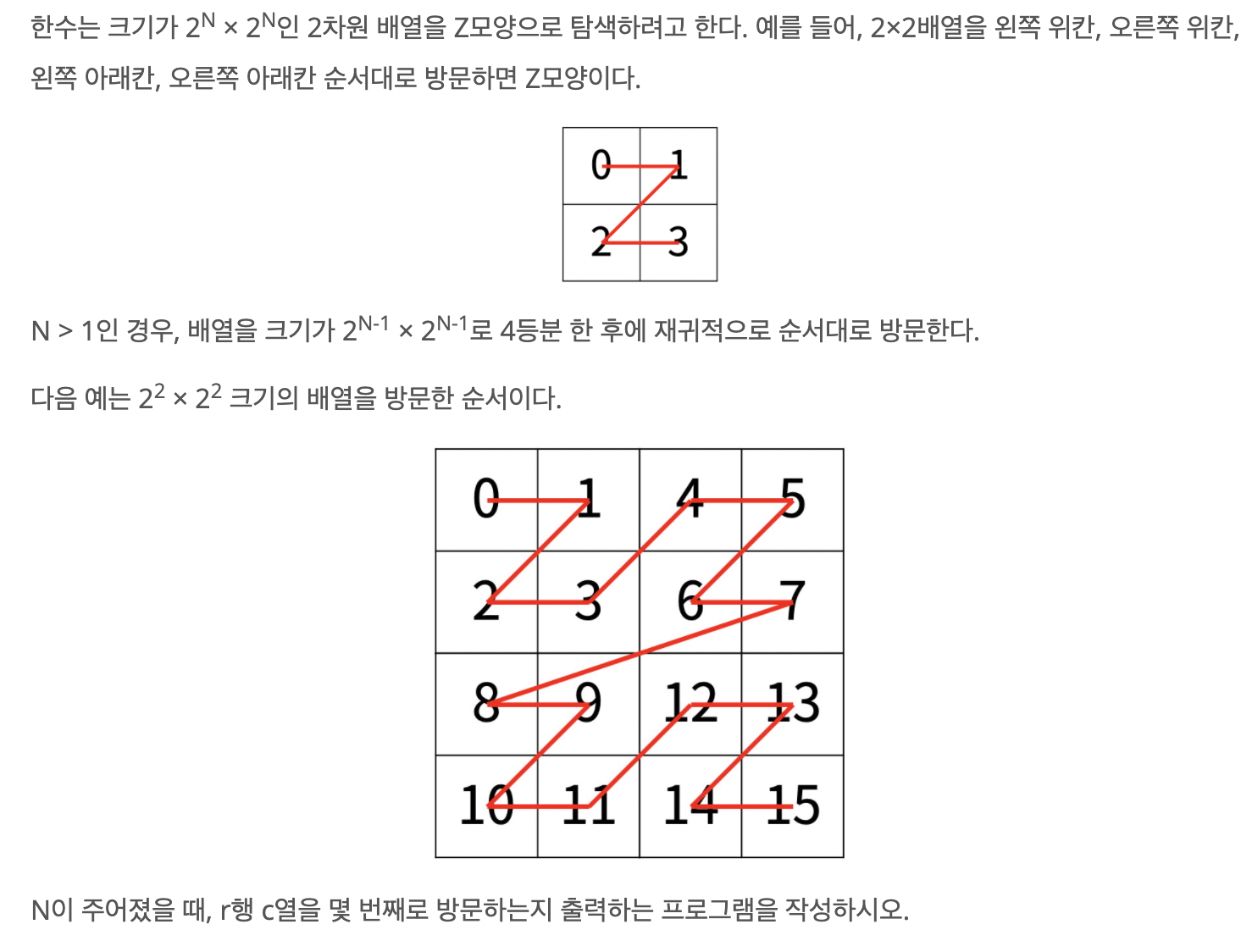
하노이탑이 아리송하지만. 백준 1074번 Z문제를 읽어 보면 '또 뭔가..' 싶을 것이다.
꾹 참고 5분만 재귀 관점으로 고민해보자.
방문 순서가 어떤 식으로 매겨지냐면, 배열을 4등분 한 후에, 1,2,3,4 순으로 진행된다.
아래 그림에서 N=3일 때, 16x16 배열을 그려놓고. 4등분 해서 영역 1,2,3,4로 나눠놨다.
r=2, c=2 칸은 '영역1'에서' 12번째로 방문한다.
'영역1' 내부를 4등분으로 나누면, 영역 1, 2, 3에 포함된 0칸~11칸을 전부 방문하고, 12번째로 방문한 셈이다.
r=6, c=2 칸은 '영역3'에서 44번째로 방문한다.
'영역3'에 오기 전에는 이미 '영역1, 영역2'를 방문한다. '영역3'내부의 0칸~11칸을 전부 방문하고, 12번째로 방문한 셈이다.
뭔가 이전에 방문한 순서를 기반으로 다음 것을 구할 때 써먹을 수 있을 것 같다는 느낌이 조금 온다. (그저 느낌뿐..)
구현을 위해 단계적으로 생각해보자.
1. 함수의 정의
직관적으로 보이는 모양 대로 정의하면 된다. 2의 N승 배열에서, (r,c)를 방문하는 순서를 반환하는 함수.
이 값이 Int범위에 들어오는지 신경써줄 필요가 있는데, n은 15이하니까 int범위를 초과하지 않는다.
int func(int n, int r, int c)
2. base condition
n=0일 때 0을 반환하도록 하자.
n=0 일 때, return 0;
3. 재귀 식
각 상황에 따른 반환 값은 아래와 같다.
여기서 half는 한 변 길이의 절반, 즉 2의 n-1승이다.
(r,c)가 1번 영역일 때, return func(n-1, r, c);
(r,c)가 2번 영역일 때, return half*half + func(n-1, r, c-half);
(r,c)가 3번 영역일 때, return 2* half*half + func(n-1, r-half, c);
(r,c)가 4번 영역일 때, return 3* half*half + func(n-1, r-half, c-half);
아까 그림을 보며 확인한 12번째 방문한다는 것의 의미를 다시 보자.
12번째 방문한다는 것은0칸~11칸을 전부 방문하고, 12번째로 방문하는 것이다.
2의 2승 을 4등분한 영역에서, 2의 1승(2의 n-1승) 영역의 1,2,3영역을 모두 방문한 다음에 4영역을 방문하고 있는 것이다.
#include <bits/stdc++.h>
using namespace std;
#define X first
#define Y second // pair에서 first, second를 줄여서 쓰기 위해서 사용
int board[502][502] =
{{1,1,1,0,1,0,0,0,0,0},
{1,0,0,0,1,0,0,0,0,0},
{1,1,1,0,1,0,0,0,0,0},
{1,1,0,0,1,0,0,0,0,0},
{0,1,0,0,0,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0,0} }; // 1이 파란 칸, 0이 빨간 칸에 대응
bool vis[502][502]; // 해당 칸을 방문했는지 여부를 저장
int n = 7, m = 10; // n = 행의 수, m = 열의 수
int dx[4] = {1,0,-1,0};
int dy[4] = {0,1,0,-1}; // 상하좌우 네 방향을 의미
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
queue<pair<int,int> > Q;
vis[0][0] = 1; // (0, 0)을 방문했다고 명시
Q.push({0,0}); // 큐에 시작점인 (0, 0)을 삽입.
while(!Q.empty()){
pair<int,int> cur = Q.front(); Q.pop();
cout << '(' << cur.X << ", " << cur.Y << ") -> ";
for(int dir = 0; dir < 4; dir++){ // 상하좌우 칸을 살펴볼 것이다.
int nx = cur.X + dx[dir];
int ny = cur.Y + dy[dir]; // nx, ny에 dir에서 정한 방향의 인접한 칸의 좌표가 들어감
if(nx < 0 || nx >= n || ny < 0 || ny >= m) continue; // 범위 밖일 경우 넘어감
if(vis[nx][ny] || board[nx][ny] != 1) continue; // 이미 방문한 칸이거나 파란 칸이 아닐 경우
vis[nx][ny] = 1; // (nx, ny)를 방문했다고 명시
Q.push({nx,ny});
}
}
}
[중요] BFS 구현 시 자주 하는 실수
1. 시작점에 방문했다는 표시를 남기지 않는다. 방문 배열에 꼭 방문 표시를 남겨야 재방문 하지 않고 무한루프로 빠지지 않는다.
2. 큐에 넣을 때 방문했다는 표시를 하는 대신 큐에서 빼낼 때 방문 했다는 표시를 남겼다. 같은 칸이 큐에 여러번 들어가서 시간초과나 메모리 초과가 날 수 있다.
3. 이웃한 원소가 유효범위를 벗어났는지에 대한 체크를 잘못했다. 배열 인덱스가 음수가 되거나 유효범위를 넘어가면 런타임 에러가 난다.
미로를 저장하는 배열을 미로 -1로 초기화해두면 굳이 방문배열을 두지 않아도 방문여부를 확인할 수 있다.
// http://boj.kr/cd14bec9ecff461ab840f853ed0eb87f
#include <bits/stdc++.h>
using namespace std;
#define X first
#define Y second
string board[102];
int dist[102][102];
int n,m;
int dx[4] = {1,0,-1,0};
int dy[4] = {0,1,0,-1};
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n >> m;
for(int i = 0; i < n; i++)
cin >> board[i];
for(int i = 0; i < n; i++) fill(dist[i],dist[i]+m,-1); // -1로 초기화한다
queue<pair<int,int> > Q;
Q.push({0,0});
dist[0][0] = 0;
while(!Q.empty()){
auto cur = Q.front(); Q.pop();
for(int dir = 0; dir < 4; dir++){
int nx = cur.X + dx[dir];
int ny = cur.Y + dy[dir];
if(nx < 0 || nx >= n || ny < 0 || ny >= m) continue; // 유효범위 확인
if(dist[nx][ny] >= 0 || board[nx][ny] != '1') continue; // 이미 방문했는지. 벽이 아닌지.
dist[nx][ny] = dist[cur.X][cur.Y]+1;
Q.push({nx,ny});
}
}
cout << dist[n-1][m-1]+1; // 문제의 특성상 거리+1이 정답
} // 바킹독님 코드
// http://boj.kr/ae38aa7eb7a44aca87e9d7928402d040
#include <bits/stdc++.h>
using namespace std;
#define X first
#define Y second
int board[1002][1002];
int dist[1002][1002];
int n,m;
int dx[4] = {1,0,-1,0};
int dy[4] = {0,1,0,-1};
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> m >> n;
queue<pair<int,int> > Q;
for(int i = 0; i < n; i++){
for(int j = 0; j < m; j++){
cin >> board[i][j];
if(board[i][j] == 1) // 익은 토마토는 시작점이니까 큐에 넣는다.
Q.push({i,j});
if(board[i][j] == 0) // 아직 안익은 토마토는 -1 로 표시한다.
dist[i][j] = -1;
}
}
while(!Q.empty()){
auto cur = Q.front(); Q.pop();
for(int dir = 0; dir < 4; dir++){
int nx = cur.X + dx[dir];
int ny = cur.Y + dy[dir];
if(nx < 0 || nx >= n || ny < 0 || ny >= m) continue; // 유효한 범위인지?
if(dist[nx][ny] >= 0) continue; // 이미 방문.
dist[nx][ny] = dist[cur.X][cur.Y]+1;
Q.push({nx,ny});
}
}
int ans = 0;
for(int i = 0; i < n; i++){
for(int j = 0; j < m; j++){
if(dist[i][j] == -1){ // 아직 익지않은 토마토가 있으면? 실패.
cout << -1;
return 0;
}
ans = max(ans, dist[i][j]); // 가장 먼 거리.
}
}
cout << ans;
}
해결 과정
1. 입력 받으면서 익은토마토만 큐에 넣는다.
2. 익지 않은 토마토는 dist 배열값을 -1로 둔다. 토마토가 없는 빈칸은 dist 배열 값이 0이다.
// http://boj.kr/aed4ec552d844acd8853111179d5775d
#include <bits/stdc++.h>
using namespace std;
#define X first
#define Y second
string board[1002];
int dist1[1002][1002]; // 불의 전파 시간
int dist2[1002][1002]; // 지훈이의 이동 시간
int n, m;
int dx[4] = {1,0,-1,0};
int dy[4] = {0,1,0,-1};
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n >> m;
for(int i = 0; i < n; i++){ // 모든 방문배열 -1로 초기화 하여 미방문 표시하기
fill(dist1[i], dist1[i]+m, -1);
fill(dist2[i], dist2[i]+m, -1);
}
for(int i = 0; i < n; i++)
cin >> board[i];
queue<pair<int,int> > Q1;
queue<pair<int,int> > Q2;
for(int i = 0; i < n; i++){
for(int j = 0; j < m; j++){
if(board[i][j] == 'F'){ // 불이면 큐1에 푸시. 거리도 배열1에 0초기화.
Q1.push({i,j});
dist1[i][j] = 0;
}
if(board[i][j] == 'J'){ // 지훈이 시작점은 큐2에 푸시. 거리도 배열2에 0초기화.
Q2.push({i,j});
dist2[i][j] = 0;
}
}
}
// 불에 대한 BFS
while(!Q1.empty()){
auto cur = Q1.front(); Q1.pop();
for(int dir = 0; dir < 4; dir++){
int nx = cur.X + dx[dir];
int ny = cur.Y + dy[dir];
if(nx < 0 || nx >= n || ny < 0 || ny >= m) continue;
if(dist1[nx][ny] >= 0 || board[nx][ny] == '#') continue; // 벽이거나 이미 방문했으면 지나감
dist1[nx][ny] = dist1[cur.X][cur.Y]+1;
Q1.push({nx,ny});
}
}
// 지훈이에 대한 BFS
while(!Q2.empty()){
auto cur = Q2.front(); Q2.pop();
for(int dir = 0; dir < 4; dir++){
int nx = cur.X + dx[dir];
int ny = cur.Y + dy[dir];
if(nx < 0 || nx >= n || ny < 0 || ny >= m){ // 범위를 벗어났다는 것은 탈출에 성공했다는 의미. 큐에 거리 순으로 들어가므로 최초에 탈출한 시간을 출력하면 됨.
cout << dist2[cur.X][cur.Y]+1;
return 0;
}
if(dist2[nx][ny] >= 0 || board[nx][ny] == '#') continue;
if(dist1[nx][ny] != -1 && dist1[nx][ny] <= dist2[cur.X][cur.Y]+1) continue; // 불의 전파 시간을 조건에 추가
dist2[nx][ny] = dist2[cur.X][cur.Y]+1;
Q2.push({nx,ny});
}
}
cout << "IMPOSSIBLE"; // 여기에 도달했다는 것은 탈출에 실패했음을 의미.
}