펜윅 트리
Fenwick Tree, Binary Indexed Tree(BIT) 라고도 한다.
구간 트리는 구간 합을 빠르게 구하는 데 주로 사용된다. 구간 트리의 진화형태가 펜윅 트리다.
펜윅 트리의 아이디어
"구간 합 대신, 부분 합만을 빠르게 구하는 자료구조를 만들어 두면 구간 합을 계산할 수 있다"
구간 합(range sum) : [3, 6] 과 같은 연속된 구간 합
부분 합(partial sum) : [0, 3] , [0, 8] 과 같이 0번 부터 i까지 합
부분 합 psum의 표현 psum[pos] = A[0] + A[1] + A[2] + ... + A[pos] 로 표현할 수 있다.
구간 [3, 6] 에 대한 합은 psum[6] - psum[2] 로 계산할 수 있다.
구간 [i, j] 에 대한 합은 psum[j] - psum[i-1] 로 계산할 수 있다.
구간 트리와 펜윅 트리의 비교
부분 합(0부터 i까지의 합)만 구한다면, 구간 트리가 미리 계산해 저장하는 상당 수는 필요가 없다.
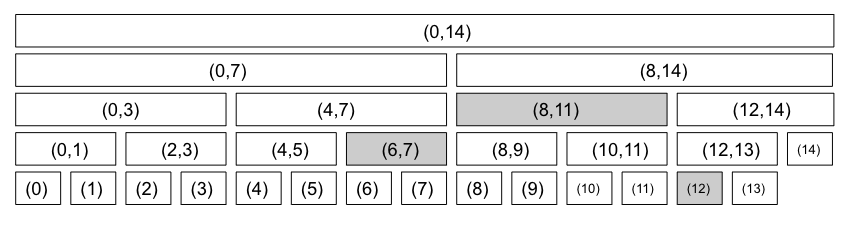
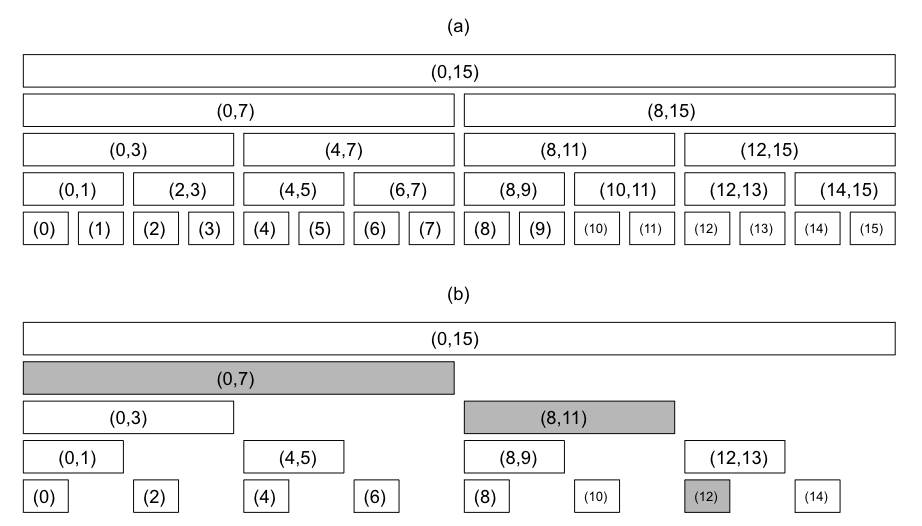
그림 (a) 는 구간트리, (b)는 펜윅 트리이다.
즉, 하나의 긴 구간 밑에 두 개의 작은 구간이 있을 때 두 구간 중 오른쪽 구간은 항상 지워도 된다.
펜윅 트리는 이 대응을 이용해 1차원 배열 하나에 각 구간의 합을 저장한다.
공간복잡도 O(n)
tree[i] = 그림 (b)에서 오른쪽 끝 위치가 A[i]인 구간의 합
구간 합 을 어떻게 계산할까?
A[pos] 까지의 구간합 psum[pos]를 계산하고 싶으면 그림 (b)에서 pos에서 끝나는 구간의 합 tree[pos]를 답에 더한다.
즉, 그림 (b)에서 색칠한 구간 tree[12], tree[11], tree[7]들은 psum[12]를 계산하기 위해 더해야 하는 구간들이다.
- 어떤 부분 합을 구하든 O(logN) 개의 구간 합만 있으면 된다
pos에서 끝나는 구간 다음으로 더해야 할 구간을 어떻게 찾을까?
- 이제 문제는 pos에서 끝나는 구간 다음으로 더해야 할 구간을 어떻게 찾을까 하는 것입니다.
- 펜윅 트리는 각 숫자의 이진수 표현을 이용해 이 문제를 해결합니다.
- 우선 이진수 표현을 위해 배열 A[]와 tree[]의 첫 원소의 인덱스를 1로 바꾼다.
- 모든 원소의 인덱스에 1을 더해 주는 것이다.
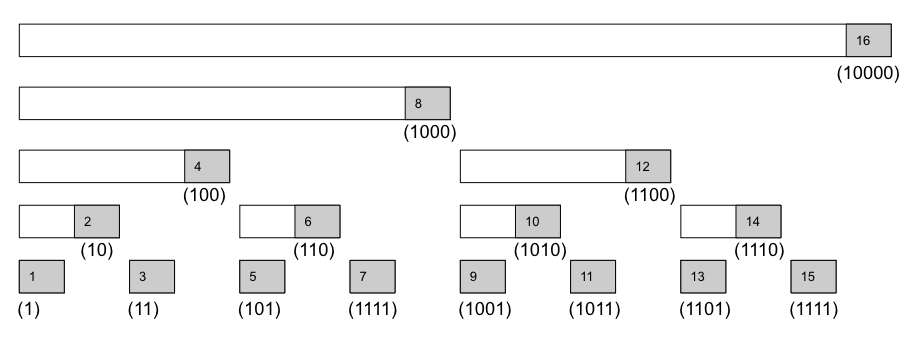
각 구간의 길이는 이진수 표현에서 오른쪽 끝에 있는 0의 개수가 하나 늘 때마다 두 배로 늘어난다.
- psum[7]을 구하기 위해 더해야 하는 숫자는
- 7에서 끝나는 구간의 합 tree[7] 111
- 6에서 끝나는 구간의 합 tree[6] 110
- 4에서 끝나는 구간의 합 tree[4] 100
- 오른쪽 끝 위치의 이진수 표현에서 마지막 비트를 지우면 다음 구간을 쉽게 찾을 수 있음
펜윅 트리 초기화
펜윅 트리를 처음 생성하면 모든 부분 합이 0으로 초기화되므로, 모든 원소가 0인 배열을 표현하게 된다.
- ex) A[5]를 3 늘리고 싶다. 이때 늘려 줘야 할 값들은
- tree[5] 101
- tree[6] 110
- tree[8] 1000
- tree[16] 10000
- 다른 경우들도 하나하나 시도해 보면 맨 오른쪽에 있는 1인 비트를 스스로에게 더해 주는 연산을 반복하면 해당 위치를 포함하는 구간들을 모두 만날 수 있음
- 예를 들어 110 에서 가장 오른쪽에 있는 비트는 10 이므로, 이를 스스로에게 더하면 1000을 얻을 수 있음
// 펜윅 트리의 구현. 가상의 배열 A[]의 부분 합을 빠르게 구현할 수 있도록 한다.
// 초기화시에는 A[]의 원소가 전부 0이라고 생각한다.
struct FenwickTree{
vector<int> tree;
FenwickTree(int n) : tree(n+1) {}
// A[0 .. pos]의 부분 합을 구한다.
int sum(int pos){
// 인덱스가 1부터 시작한다고 생각 (비트연산 활용을 위해서)
++pos;
int ret = 0;
while(pos > 0){
ret += tree[pos];
// 다음 구간을 찾기 위해 최종 비트를 지운다
pos &= (pos-1);
}
return ret;
}
// A[pos]에 val을 더한다
void add(int pos, int val){
++pos;
while(pos < tree.size()){
tree[pos] += val;
pos += (pos & -pos); // -pos : 음수 표현을 위해 비트별 NOT연산을 하고 1을 더한다
}
}
};참고
알고리즘 문제해결전략 (구종만 저)
'알고리즘 > 알고리즘 C' 카테고리의 다른 글
| 구간트리 (세그먼트 트리) (0) | 2020.08.12 |
|---|---|
| 최소 스패닝 트리 (0) | 2020.08.12 |
| 그래프의 정의와 표현방법 (2) | 2020.08.02 |
| 우선순위 큐 (0) | 2020.06.03 |
| 삽입 정렬 (중요) (0) | 2020.06.02 |