목차
0x00 다이나믹 프로그래밍 설명
0x01 연습 문제
0x02 경로 추적
0x00 다이나믹 프로그래밍 설명

다이나믹 프로그래밍은 여러 개의 하위 문제를 먼저 푼 후, 그 결과를 활용하여 문제를 해결하는 알고리즘이다.
앞 글자만 따서 DP라고 부르기도 한다.
재귀를 배울 때 피보나치 문제를 풀어봤다.
재귀적으로 구현하면, fibo(4)를 호출할 때 fibo(3)과 fibo(2)를 호출한다.
fibo(3)은 또 fibo(2)와 fibo(1)을 호출하고. fibo(2)는 fibo(1)과 fibo(0)을 호출한다.
-> 중복된 연산 발생!
int fibo(int n){
if(n <= 1) return 1;
return fibo(n-1) + fibo(n-2);
}피보나치 문제를 DP로 해결하면, 연산의 결과를 배열에 저장하는 메모이제이션을 활용한다.
그래서 fibo(1)을 재호출하지 않고 f[1]의 값을 재활용한다.
int fibo(int n){
int f[20];
f[0] = f[1] = 1;
for(int i = 2; i <= n; i++)
f[i] = f[i-1] + f[i-2];
return f[n];
}연산의 중간 결과를 저장하여 재활용 하니까. O(N)에 답을 구할 수 있다.
DP를 푸는 과정
1. 테이블 정의하기
2. 점화식 찾기
3. 초기값 정하기
DP는 점화식 찾고, 초기값을 채워넣은 후에 반복문을 돌면서 배열을 채우면 구현이 끝나는 단순한 구조다.
DP에 익숙하지 않으면 DP문제인지도 알아채지 못할 수도 있다. 여러 문제를 풀면서 DP 점화식을 찾는 연습을 하자.
0x01 연습 문제 : 1로 만들기 BOJ 1463
이 문제는 BFS로도 해결할 수 있다. dist 배열을 두고 초기값을 1로 한 뒤, x2, x3, +1로 뻗어나가면 답이 나온다.
그런데 DP로 풀면 훨씬 짤막하게 구현할 수 있다.
1. 테이블 정의하기
먼저 테이블은 위와 같이 정의하자. D[i] = i를 1로 만들기 위해 필요한 연산 횟수의 최솟값
배열의 인덱스와 값을 어떻게 구성할지에 관한 건 여러 경험이 쌓이면 감이 온다.
2. 점화식 찾기
구체적인 예시를 들어서 D[12]를 구하는 연산을 생각해보자.
D[12] = 12를 1로 만들기 위해 필요한 연산 횟수의 최솟값
3으로 나눈다: D[12] = D[4] + 1번의 연산(3으로 나누기)
2로 나눈다: D[12] = D[6] + 1번의 연산(2로 나누기)
1을 뺀다 D[12] = D[11] + 1번의 연산(1 빼기)
세 가지 연산 횟수 중에서 최솟값이 답이 된다. 따라서 D[12] = min( D[4] + 1, D[6] + 1, D[11] + 1)
3. 초기값 정의하기
1을 1로 만드는데 연산은 0번 필요하다. D[1] = 0
2를 1로 만드는데 연산은 1번 필요하다.(2로 나누거나 1을 빼기) D[2] = 1
이 문제에서는 D[1] 초기값만 정해주면 된다.
이제 D[] 배열을 전역에 잡고 for문을 돌면서 주어진 정수x 인덱스까지 채우면 답이 나온다.
// http://boj.kr/161694ef04f04d8dbe826e253622c1cb
#include <bits/stdc++.h>
using namespace std;
int d[1000005];
int n;
int main(void) {
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n;
d[1] = 0;
for(int i = 2; i <= n; i++){
d[i] = d[i-1]+1;
if(i%2 == 0) d[i] = min(d[i],d[i/2]+1);
if(i%3 == 0) d[i] = min(d[i],d[i/3]+1);
}
cout << d[n];
}DP는 구현이 이렇게 짤막한 편이다. 점화식을 찾아내는 것이 관건이다.
0x01 연습 문제 : 1,2,3 더하기 BOJ 9095

1. 테이블 정의하기
정수 4를 1,2,3의 합으로 나타내는 방법의 수는 본문에 나와 있지만 7가지다.
테이블은 D[4] = 7 의 형태로 만들면 된다. D[i] = i를 1,2,3의 합으로 나타내는 방법의 수.
7가지 방법을 3줄에 나눠서 써놨다. 규칙이 뭘까? 점화식을 생각해보자.
첫 번째 줄은 +1로 끝난다.
두 번째 줄은 +2로 끝난다.
세 번째 줄은 +3으로 끝난다.

2. 점화식 찾기 : 노랑으로 표시된 +1, +2, +3만 제외하고 생각해보자.
| 1+1+1, 3, 2+1, 1+2 | 3을 1,2,3의 합으로 나타내는 방법 == D[3] |
| 1+1, 2 | 2를 1,2,3의 합으로 나타내는 방법 == D[2] |
| 1 | 1을 1,2,3의 합으로 나타내는 방법 == D[1] |
3을 1,2,3의 합으로 나타내는 방법에 +1, +2, +3 을 붙이면 4가 된다.
| 1+1+1+1, 3+1, 2+1+1, 1+2+1 | 3을 1,2,3의 합으로 나타내는 방법 +1 |
| 1+1+2, 2+2 | 2를 1,2,3의 합으로 나타내는 방법 +2 |
| 1+3 | 1을 1,2,3의 합으로 나타내는 방법 +3 |
이렇게 D[4]=D[3] + D[2] + D[1] 이 성립하게 된다.
3. 초기값 정하기
D[i] 는 직전 값이 3개는 필요하다. D[i] = D[i-1] + D[i-2] + D[i-3]
D[1] = 1, D[2] =2, D[3] = 4.
// http://boj.kr/8b763a1df15a4cb3936f7a181f3db97c
#include <bits/stdc++.h>
using namespace std;
// d[i] = i를 1, 2, 3의 합으로 나타내는 방법의 수
int d[20];
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
d[1] = 1; d[2] = 2; d[3] = 4;
for(int i = 4; i < 11; i++)
d[i] = d[i-1] + d[i-2] + d[i-3];
int t;
cin >> t;
while(t--){
int n;
cin >> n;
cout << d[n] << '\n';
}
}0x01 연습 문제 : 계단 오르기 BOJ 2579
만약 N이 20 정도로 그다지 크지 않으면 백트래킹 같은 방법으로 O(N^2)으로 해결이 가능하다.
지금처럼 N이 300이라면 DP로 해결해야 한다.
2개의 규칙을 유념하자.
1) 최종 계단은 반드시 밟아야 한다.
2) 계단을 연속 3개 밟을 수 없다.
1. 테이블 정의하기
S[k] = 주어진 계단 점수
D[i] = i 번째 계단까지 최대 점수
2. 점화식 찾기
최종 계단은 반드시 밟아야 하니까, 그 이전 계단에 대해서만 생각하자.
계단이 4개 있을 때 가능한 경우 2가지를 그림으로 그렸다.
경우 2 : 4번째 계단이 2연속 밟은 계단이면, 직전 계단은 반드시 밟는다.
경우 1 : 4번째 계단이 1연속 밟은 계단이면, 직전 계단은 반드시 안밟는다.
경우 1 : 최종 계단이 2번째 연속으로 밟은 계단이면, 확실한건 3번은 밟았고 2번은 안밟는다는 것이다.
따라서 1번째 계단까지의 최대점수(D[1]) + 3번 점수(S[3]) + 4번 점수(S[4]) 가 답이 된다.
| 계단 번호 | 1 | 2 | 3 | 4 |
| 밟았는지 | ? | X | O1 | O2 |
경우 2 : 최종 계단이 1번째 연속으로 밟은 계단이면, 확실한건 3번은 안밟았다는 것이다.
따라서 2번째 계단까지의 최대점수(D[2]) + 4번 점수(S[4]) 가 답이 된다.
| 계단 번호 | 1 | 2 | 3 | 4 |
| 밟았는지 | ? | X | O1 |
점화식은 아래와 같다.
D[i] = S[i] + max(S[i-1] + D[i-3] , D[i-2]);
3. 초기값 정하기
i를 구할 때 i-3 이 필요하니까 1, 2, 3 까지 초기값을 정해줘야 한다.
D[1] = S[1], D[2] = S[2], D[3] = S[3];
// http://boj.kr/e93e56bb850a46378cf8f53486233cdc
#include <bits/stdc++.h>
using namespace std;
int s[305];
int n;
int d[305];
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n;
int tot = 0;
for(int i = 1; i <= n; i++){
cin >> s[i];
tot += s[i];
}
if(n <= 2){
cout << tot;
return 0;
}
d[1] = s[1];
d[2] = s[2];
d[3] = s[3];
for(int i = 4; i <= n-1; i++) d[i] = min(d[i-2],d[i-3])+s[i];
cout << tot - min(d[n-1],d[n-2]);
}0x01 연습 문제 : RGB거리 BOJ 1149
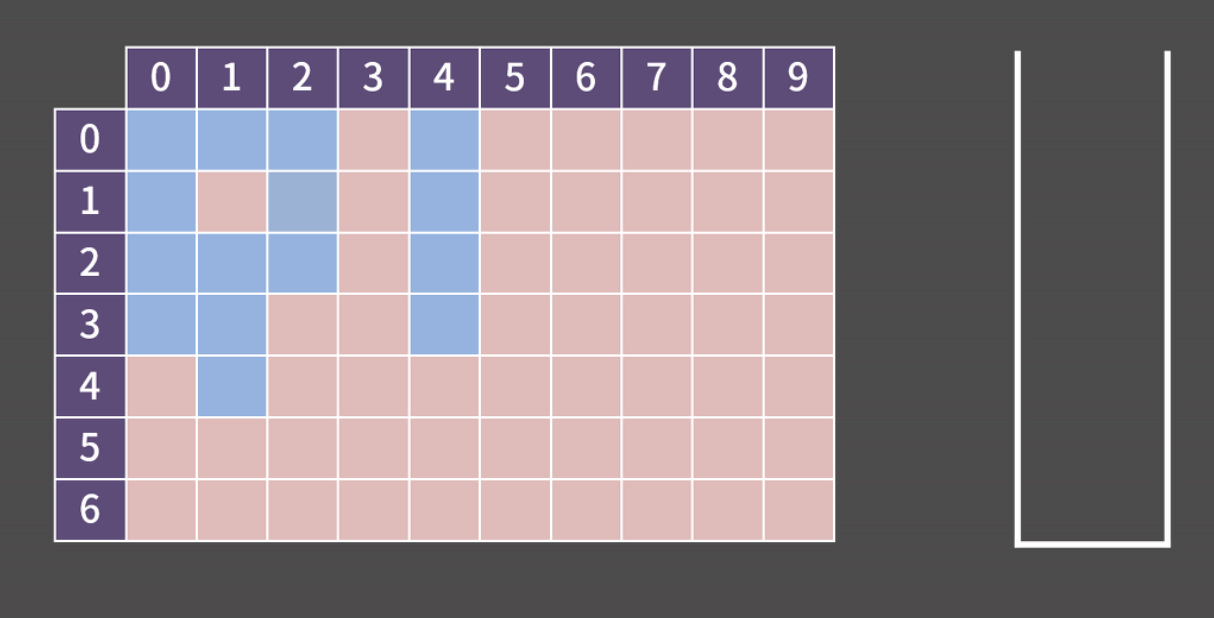
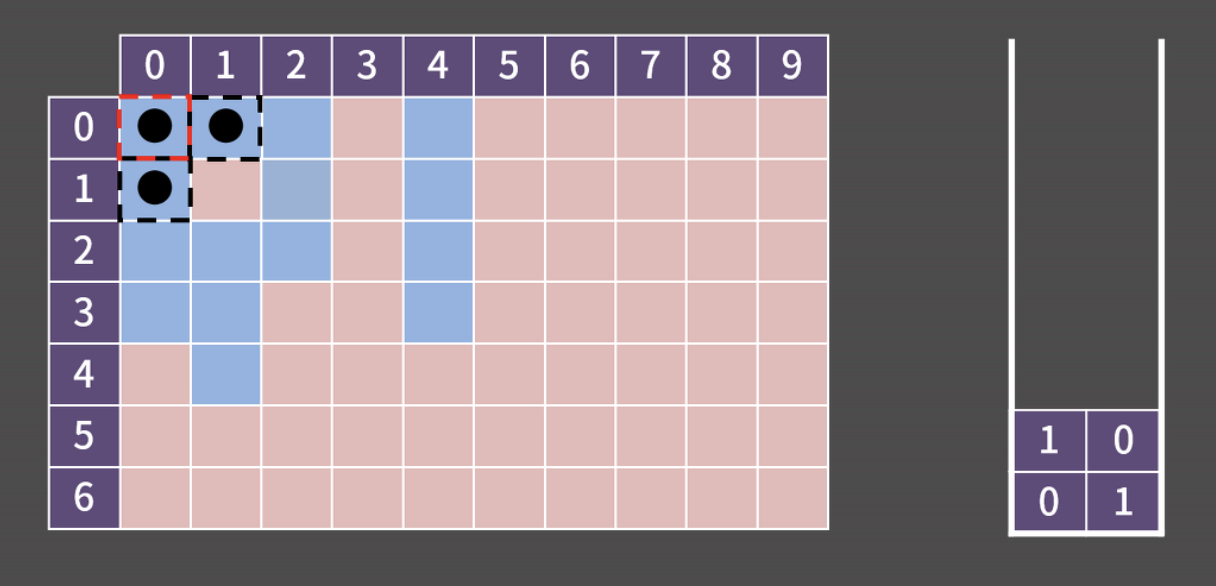
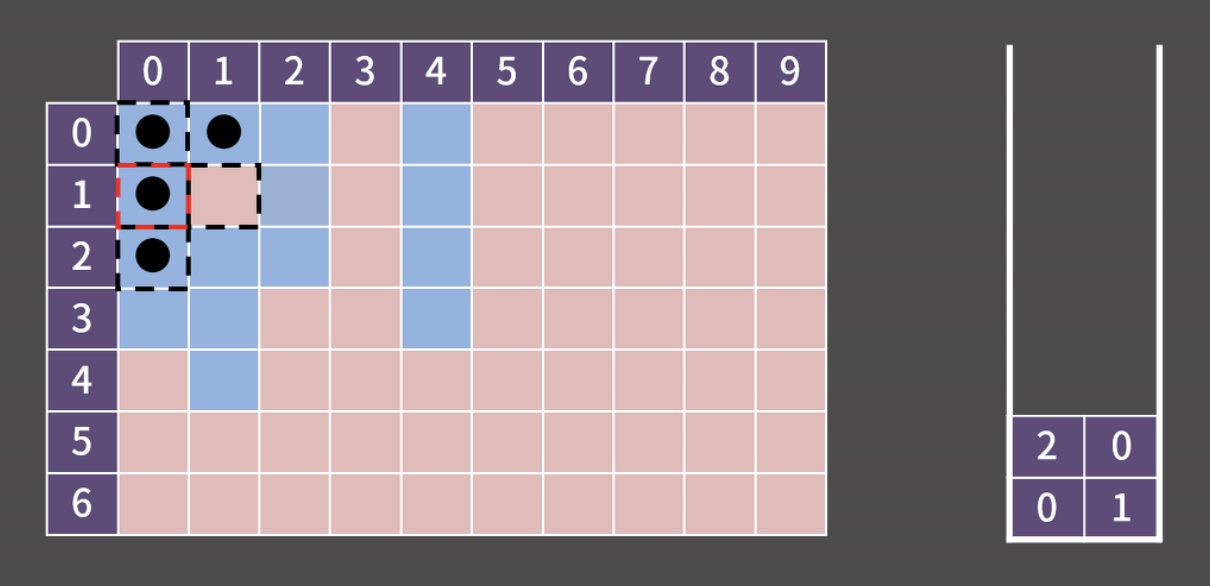
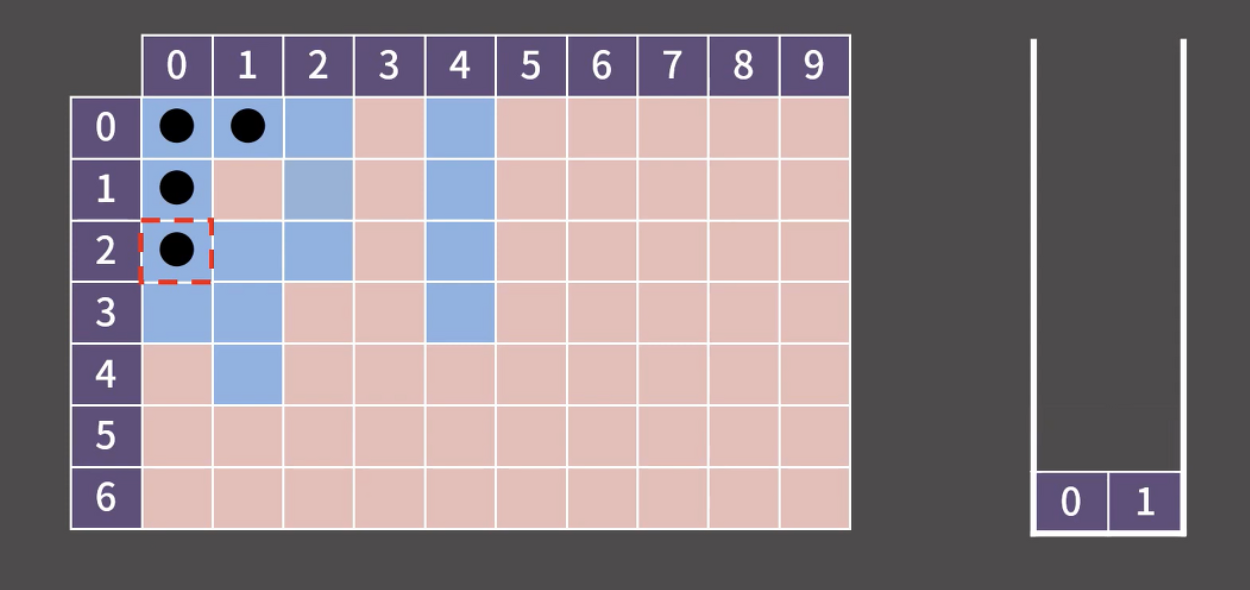
0x02 경로 추적 : 1로 만들기 2 BOJ 12852
DP 문제집
| 백준 문제 번호 | 내 코드 |
| 1463 1로 만들기 | 내 코드 |
| 9095 1,2,3더하기 | 내 코드 |
| 2579 계단 오르기 | 내 코드 |
| 1149 RGB거리 | 내 코드 |
| 11726 2xn 타일링 | 내 코드 |
| 11659 구간 합 구하기 4 | 내 코드 |
| 12852 1로 만들기 2 | 내 코드 |
| 1003 피보나치 함수 | 내 코드 |
다음 시간에는 그리디 알고리즘을 공부한다.
공부 내용 출처 : 바킹독 알고리즘 다이나믹 프로그래밍
'알고리즘 > 실전 알고리즘' 카테고리의 다른 글
| 0x0F강 - 정렬2 (0) | 2021.12.18 |
|---|---|
| 0x0E강 - 정렬1 (0) | 2021.12.11 |
| 0x0C강 - 백트래킹 (0) | 2021.12.10 |
| 0x0B강 - 재귀 (0) | 2021.12.08 |
| 0x0A강 - DFS (0) | 2021.12.07 |