목차
0x00 Counting Sort
0x01 Radix Sort
0x02 STL Sort
0x03 정렬의 응용
0x00 Counting Sort
{ 1, 5, 4, 2, 3, 1, 4, 3}
이 수열을 숫자 크기를 기준으로 오름차순으로 정렬하려고 한다. 어떻게 할지 생각해보자.
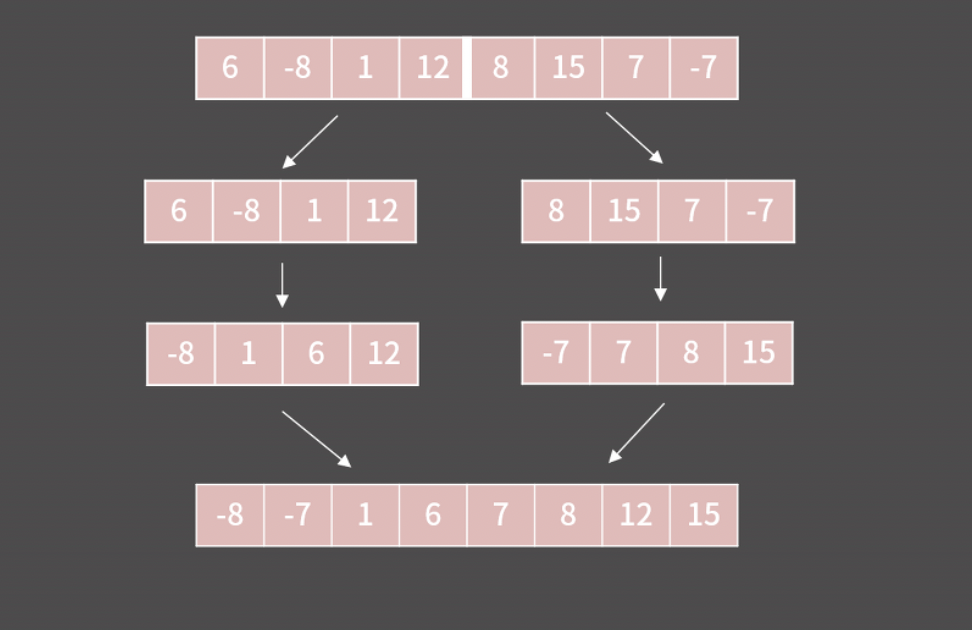
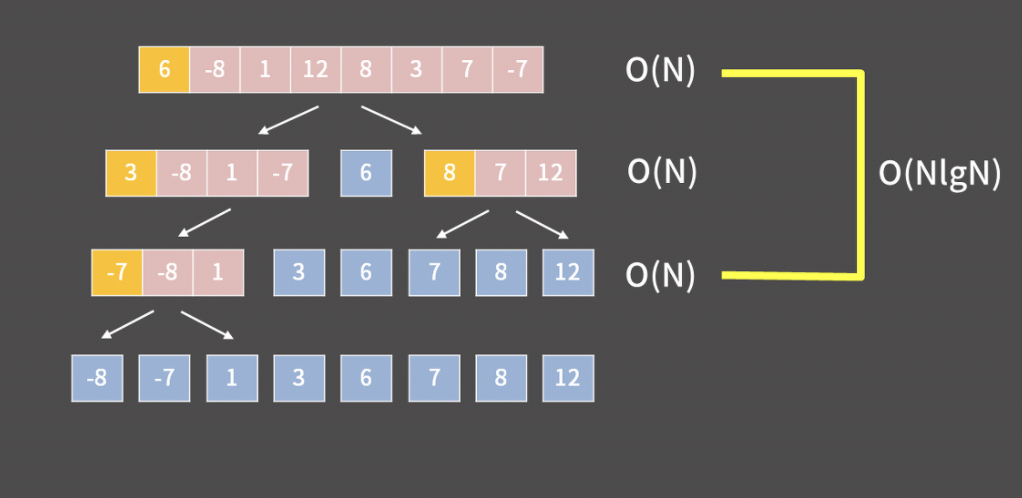
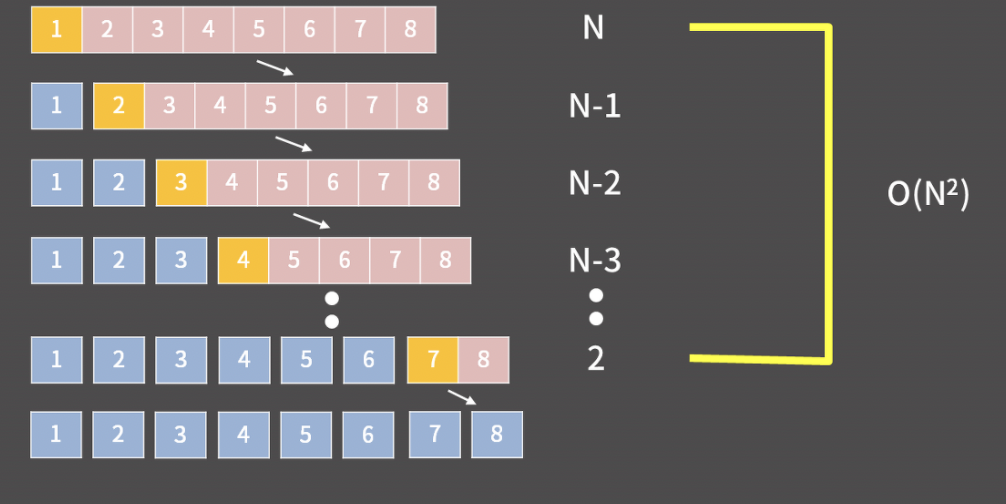
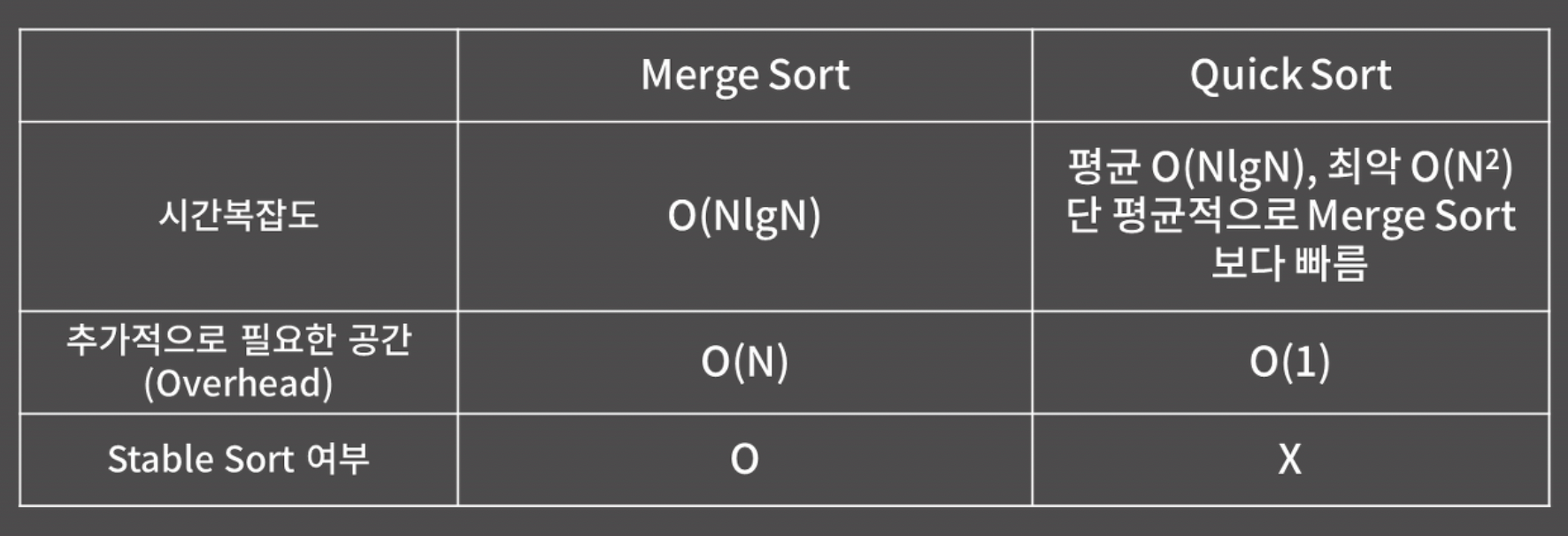
머지 소트나 퀵 소트를 써도 된다.
여기서 다시 짚고 넘어갈 점!
퀵 소트는 NlogN이 보장 된다 안 된다?
최악의 경우 O(N^2)이다. 꼭 기억하자.
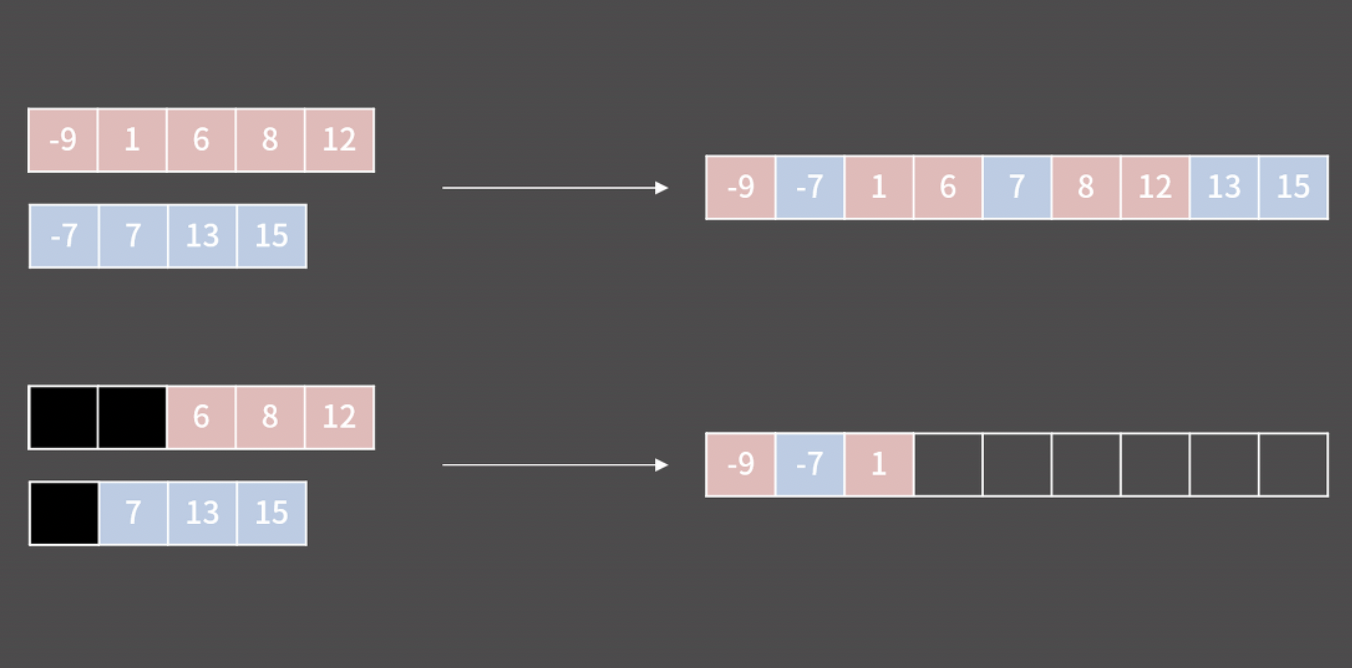
이 수열을 조금 변형한 다음에, 정렬하자. 아래의 표가 어떤 것을 의미할까?

-> 수열에 숫자가 포함된 횟수를 저장했다.
1이 2번 나왔다. 2가 1번 나왔다. 3이 2번 나왔다 ...
이 표만 있으면 각 숫자가 차례로 나온 횟수만 적으면 정렬이 가능하다! 이런 알고리즘이 카운팅 소트다.
이 때, '최솟값과 최댓값을 커버할 수 있는 크기의 배열을 선언해도 되는지' 문제의 메모리 제한을 확인해야 한다.
512MB 제한이면, int 기준 1.2억인 배열을 잡을 수 있다.
대략 1000만 이하일 때, 카운팅 소트를 쓸 수 있다고 생각하면 된다.
백준 15688번 수 정렬하기5 문제를 카운팅 소트로 풀어보자. (내 코드, 바킹독님 코드)
// http://boj.kr/eeee207545644480a1971a2723769d93 바킹독님코드
#include <bits/stdc++.h>
using namespace std;
int freq[2000001];
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
int n;
cin >> n;
for(int i = 0; i < n; i++){
int a;
cin >> a;
freq[a+1000000]++;
}
for(int i = 0; i <= 2000000; i++){
while(freq[i]--){ // cnt[i]번 반복
cout << i-1000000 << '\n';
}
}
}입력 숫자가 음수 양수 모두를 포함하니까 애초에 모든 수에 100만을 더한 코드다.
시간복잡도를 생각해보자.
수의 범위가 K라고 할 때.
1) 처음에 N개의 숫자들을 배열에 넣는다.
2) 정렬할 때 K개의 칸을 확인한다.
따라서 시간복잡도는 O(N+K)가 된다.
이렇게 수의 범위가 제한되어 있고 작은 경우에 카운팅 소트가 유용하다.
0x01 Radix Sort(기수 정렬)
라딕스 소트는 자릿수를 이용해서 정렬하는 알고리즘이다.
카운팅 소트를 응용한 것으로 이해하면 된다.
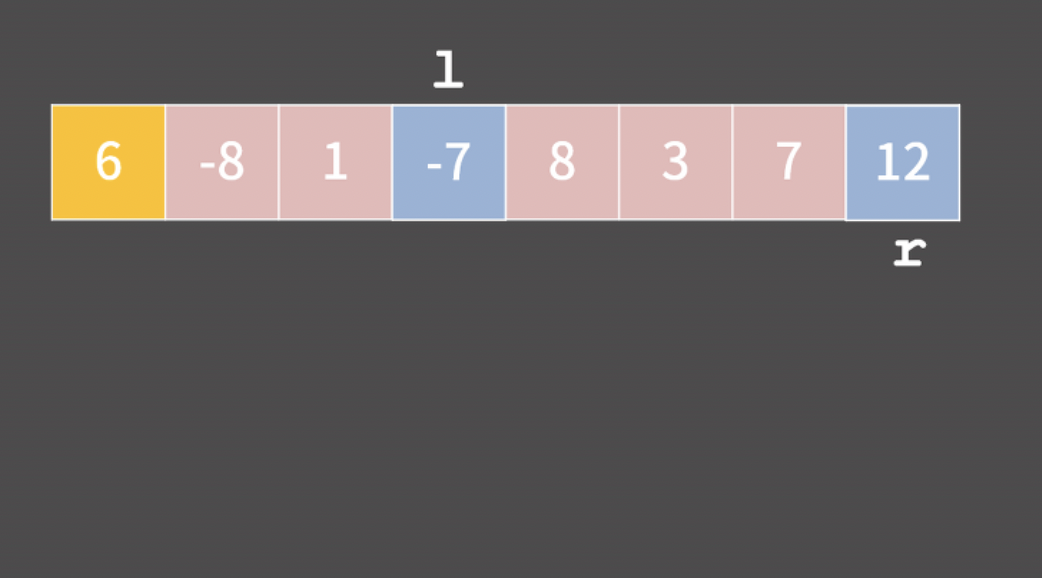
아래 수열을 라딕스 소트로 정렬해보자

012 는 12를 의미하는데. 편의를 위해 앞에 0을 붙였다.


1. 크기 10의 리스트를 선언한다.
2. 숫자의 '1의 자리'에 맞춰서 리스트에 넣는다.
012는 1의 자리가 2다. 따라서 인덱스 2에 넣는다. 421은 인덱스 1에 넣자.
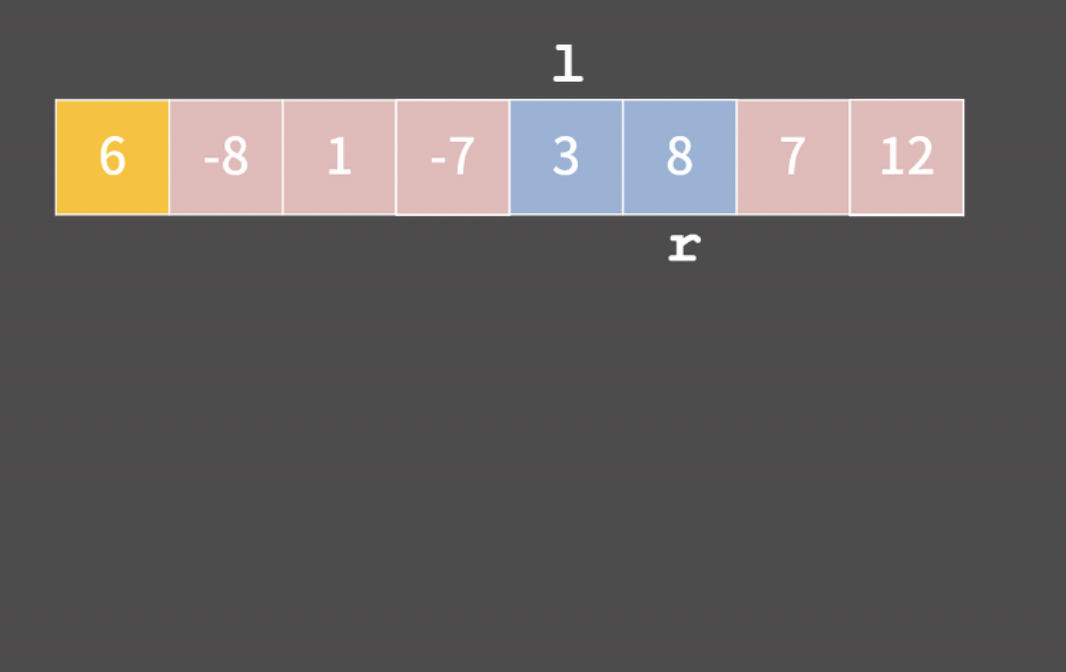
3. 0번 리스트부터 보면서 수를 꺼내서 수열을 재배열한다.

이 과정을 거치면 수열이 '1의 자리'를 기준으로 재배열된다.
1의 자리 기준이고 주어진 수열의 자리가 유지되니까 421이 021보다 앞에 온다.

4. 다음 단계는 '10의 자리'에 맞춰서 리스트에 넣는다.
100은 10의 자리가 0이니까 인덱스 0에 넣는다. 421은 인덱스 2에 넣는다.
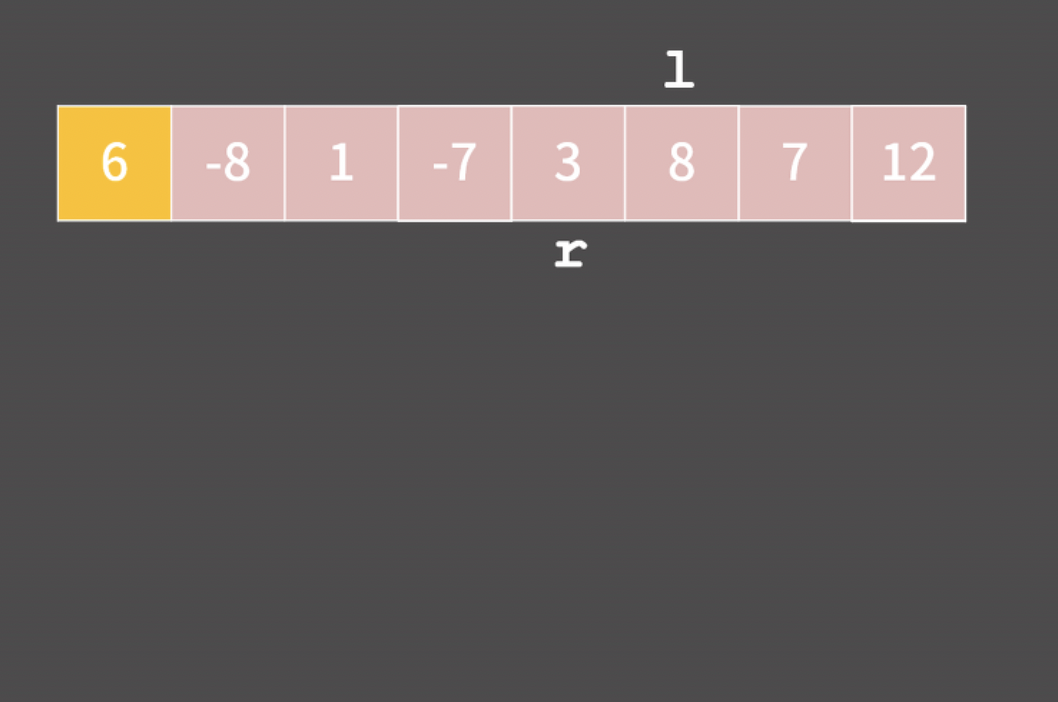
5. 0번 인덱스 부터 9번 인덱스를 보면서 수를 꺼내서 재배열한다.

5. 다음 단계는 '100의 자리'에 맞춰서 리스트에 넣는다.
100은 100의 자리가 1이니까 인덱스 1에 넣는다. 502는 인덱스 5에 넣는다.
6. 하란대로 하니깐 일단. 1의 자리 -> 10의 자리 -> 100의 자리 순으로 재배열 하니까 정렬이 완료됬다.

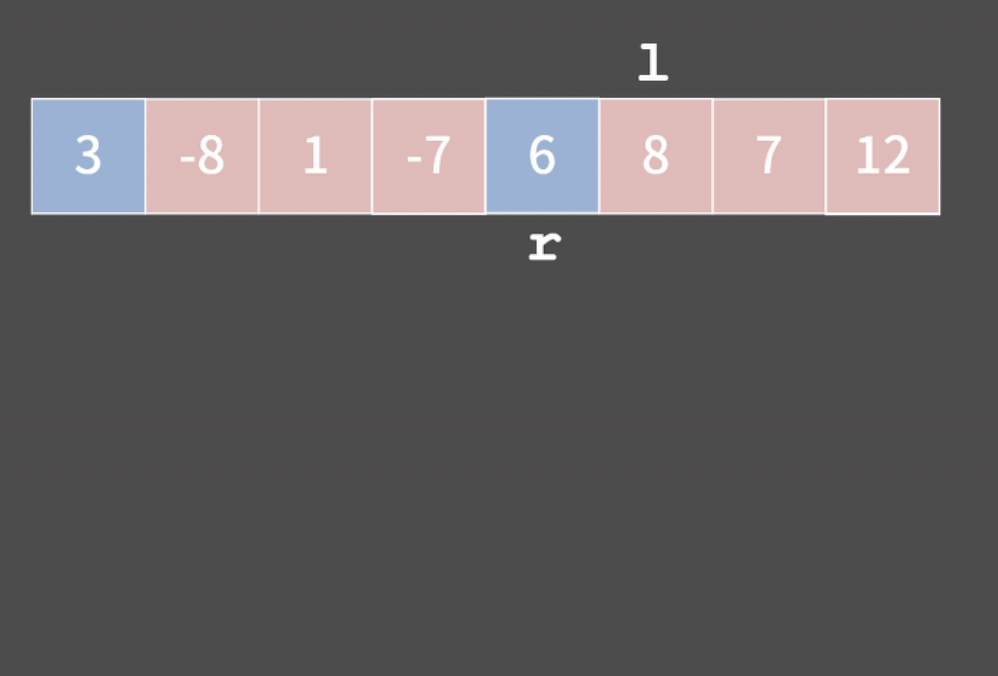
여기서 질문. 502는 왜 421보다 클까?
왜 이럴까를 생각해보면 라딕스 소트를 이해하는데 도움이 된다.
502와 421을 비교할 때, 먼저 100의 자리를 비교한다. 100의 자리만 보면, 5 > 4 이니까!
즉, 수A 가 수B보다 크다는 의미는 더 큰 자릿수에서 A의 자릿수가 B의 자릿수보다 큰 경우가 먼저 생긴다는 것이다.
이걸 인지한 상태로 라딕스 소트 과정을 보자.

10의 자리 까지는 502가 421 앞에 위치했다.
하지만 100의 자리 비교 단계에서는 421는 4번 인덱스에 들어가고. 502는 5번 인덱스에 들어가기 때문에.
결국 421이 502보다 앞에 오도록 올바르게 정렬된다.
라딕스 소트의 시간복잡도
1의 자리 기준으로 재배열 하면서 리스트 크기 만큼 순회했다.
10의 자리 기준으로 재배열 할 때도 리스트 크기 만큼 순회했다.
따라서 자릿수의 최대 개수가 D개라고 할 때, D번에 걸쳐서 카운팅 소트를 하는 것과 똑같다.
리스트의 크기를 K개 라고 할 때, 엄밀하게 말하면 시간 복잡도는 O(D(N+K))이지만.
보통 리스트의 개수는 N에 비해 무시가 가능할 정도로 작다. 당장 지금 예시로 든 상황도 리스트 갯수 K가 10밖에 안된다.
결론적으로 라딕스 소트의 시간복잡도는 O(DN)이다.
적어도 코딩 테스트에서는 라딕스 소트를 구현해야 하는 상황은 아예 없다. 개념만 이해하자.
라딕스 소트 구현 코드
#include <bits/stdc++.h>
using namespace std;
int n = 15;
int arr[1000001] = {12, 421, 46, 674, 103, 502, 7, 100, 21, 545, 722, 227, 62, 91, 240};
int d = 3; // 자릿수의 최대 길이.
int p10[3]; // p10[i] = 10의 i승
// x의 10^a 자리의 값을 반환하는 함수
int digitNum(int x, int a) {
return (x / p10[a]) % 10;
}
vector<int> l[10]; // 0부터 9까지 저장.
int main(void) {
ios::sync_with_stdio(0);
cin.tie(0);
p10[0] = 1;
for(int i = 1; i < d; i++) p10[i] = p10[i-1] * 10;
for(int i = 0; i < d; i++){ // 1의 자리 -> 10의 자리 -> 100의 자리.
for(int j = 0; j < 10; j++) l[j].clear();
// 각 수를 list에 대입
for(int j = 0; j < n; j++) // 0~9
l[digitNum(arr[j], i)].push_back(arr[j]);
// 0번 리스트 부터 차례로 다시 arr에 넣어 재배열
int aidx = 0;
for(int j = 0; j < 10; j++){
for(auto x : l[j]) arr[aidx++] = x;
}
}
for(int i = 0; i < n; i++) cout << arr[i] << ' ';
return 0;
}
코드를 간단히 짚고 넘어가면. n은 배열 크기, arr은 정렬할 배열이다.
d는 자릿수의 최댓값이다. (100의자리가 최대니까 여기서는 d가 3이 된다.)
배열 p10은 10의 지수를 저장할 배열이다. p10[0] == 1 , p10[1] = 10, p10[2] = 100
// x의 10^a 자리의 값을 반환하는 함수
int digitNum(int x, int a){
return (x / p10[a]) % 10;
}
digitNum함수는 x에서 10의 a자리 숫자를 추출한다. ex) digitNum(253, 1) 의 리턴값은 5다.
vector<int> l 은 0번부터 9까지를 저장하는 리스트다.
p10[i]는 10의 i승을 저장할 변수다. p10배열 초기화 코드인데. 정수 거듭제곱을 계산해야 하면 이렇게 하는 것이 정석이다.
p10[0] = 1; // 10의 0승이니까 1이다.
for(int i = 1; i < d; i++) p10[i] = p10[i-1] * 10;
pow 함수는 실수형을 반환하기 때문이다. 아래 코드 처럼 쓰면 실수 오차로 꼬일 수 있다. 주의하자. pow함수 레퍼런스
p10[i] = pow(10, i);
// double pow (double base, double exponent);정렬 과정에 '비교'를 하는지?
| Comparision Sort | Non-comparision Sort |
| 버블 소트 머지 소트 퀵 소트 |
카운팅 소트 라딕스 소트 |
카운팅 소트와 라딕스 소트는 정렬 과정에 '비교'를 하지 않는다.
0x02 STL sort
algorithm 헤더에서 제공하는 sort() 함수는 기본으로 오름차순으로 정렬해준다.
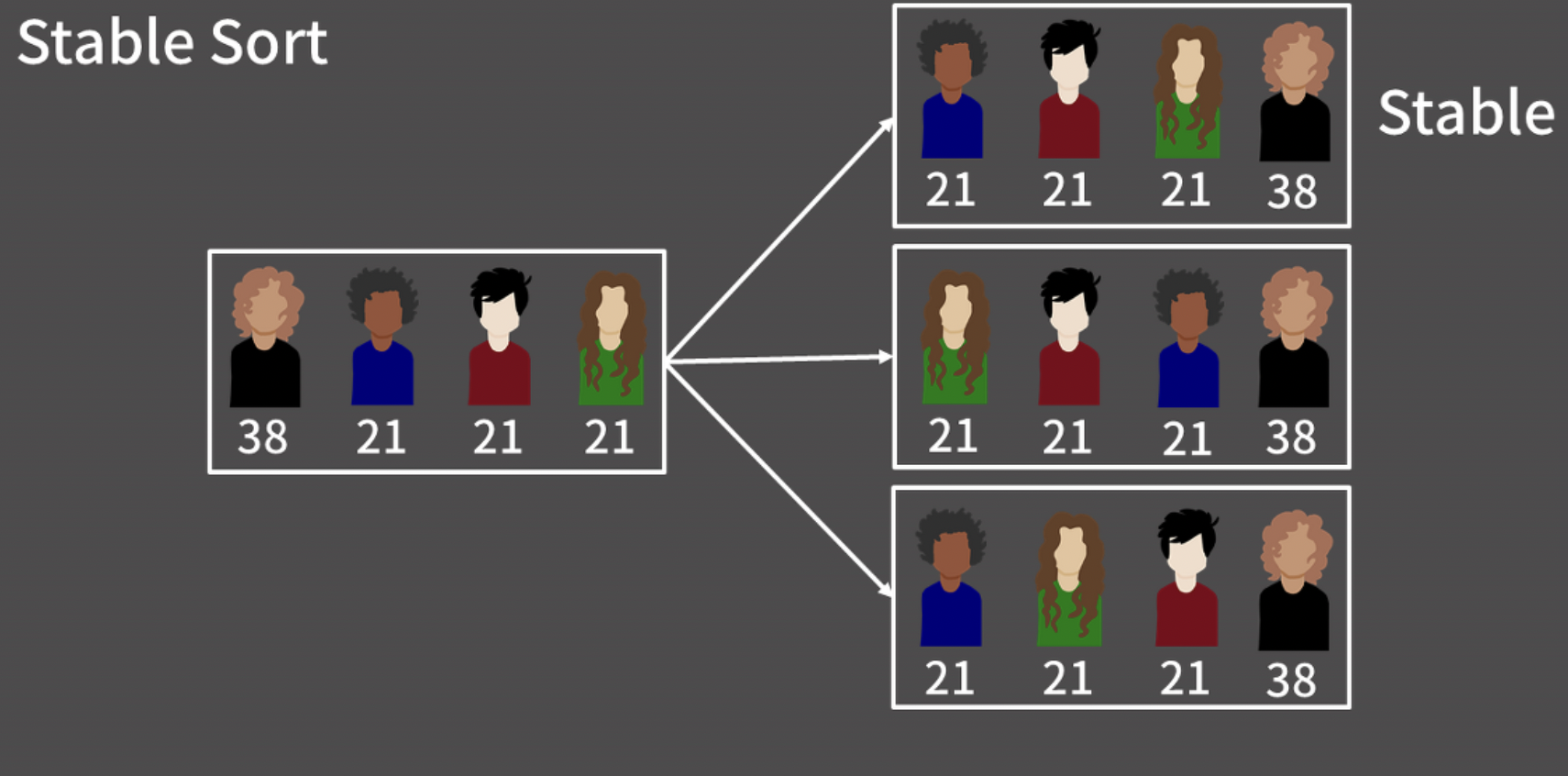
최악의 경우에도 O(NlogN)이 보장된다. 단 stable sort가 필요하다면 sort()가 아닌 stable_sort()를 쓰자.
sort() 레퍼런스
int a[5] = {1, 4, 5, 2, 7};
sort(a, a+5);
vector<int> b = {1, 4, 5, 2, 7};
sort(b.begin(), b.end()); // or sort(b.begin(), b.begin() + 5 );stable_sort() 레퍼런스
두 원소의 우선순위가 같다면 원소의 위치를 변경하지 않는다. 사용법은 sort()와 똑같다.
[중요] 비교 함수
sort() 함수의 파라미터로 비교함수를 넘길 수 있다. stable_sort()도 마찬가지다.
예를 들어, int형을 5로 나눈 나머지 순으로, 5로 나눈 나머지가 같다면 크기 순으로 정렬하고 싶으면 아래 코드처럼 하면 된다.
비교함수 cmp는 a가 b의 앞에 와야할 때 true를, 그렇지 않을 때 false를 반환한다.
bool cmp(int a, int b){ // a가 b의 앞에 와야할 때 true, 아니면 false
if(a % 5 != b % 5) return a % 5 < b % 5;
else a < b;
}
int a[7] = {1, 2, 3, 4, 5, 6, 7};
sort(a, a+7, cmp);
// 출력 결과: 5 1 6 2 7 3 4
비교함수 구현 시 자주하는 실수
1. a가 b의 앞에 와야할 때만 true를 반환한다. a==b 라면 false를 반환한다.
예를 들어, 수열을 크기의 내림차순으로 정렬하고 싶을 때, a와 b가 같은 경우 false를 반환하니까 런타임 에러가 발생할 수 있다.
bool cmp(int a, int b){ // [런타임 에러 발생]
if(a >= b) return true;
return false;
}a > b 일 때 true를 반환하도록 수정하자.
bool cmp(int a, int b){ // 올바른 형태
return a > b;
}2. 비교 함수의 인자로 STL 혹은 클래스 객체를 전달시 reference를 사용하자.
문자열을 받아서 끝자리의 알파벳 순으로 정렬하고 싶어서 비교함수를 작성했다.
아래의 비교함수는 어떻게 개선하면 좋을까?
bool cmp(string a, string b){
return a.back() < b.back();
}
// 함수의 인자로 STL이나 구조체 객체를 보내면 값의 '복사'가 일어난다!함수의 인자로 STL이나 구조체 객체를 보내면 값의 '복사'가 일어남을 기억하자!
이 경우, 굳이 복사라는 불필요한 연산이 없어도 비교가 가능하다.
따라서 복사를 하는 대신 아래처럼 reference를 보내는 것이 더 바람직하다.
bool cmp(const string& a, const string& b){ // 레퍼런스를 보내서 비교하는 것이 효율적.
return a.back() < b.back();
}
const string& a, const string& b라고 쓰면 a와 b는 변하지 않음을 명시적으로 나타내기 때문에 가독성이 도움이 된다.
하지만 코딩테스트에서 const를 안써도 크게 상관은 없다.
비교함수 연습을 위해 백준 1431번 시리얼 번호 문제를 풀고 오자. 1431 내 코드
0x03 정렬의 응용
정렬을 이용해서 시간복잡도를 개선할 수 있는 문제 백준 11652번 카드 문제를 확인해보자.
O(N^2)의 풀이는 너무 직관적으로 보인다. 그런데 O(N^2)이면 시간초과이고. 수의 범위가 매우 크다.
map은 아직 배우지 않았고. 또 이진검색트리라는 개념을 사용하는 만큼 map을 이용한 풀이는 배제하겠다.
어떻게 해결해야 할까?

일단 변수 3개가 필요하다.
cnt : 현재 보고 있는 수의 등장 횟수.
mxval : 현재까지 가장 많이 등장한 수의 값.
mxcnt : 현재까지 가장 많이 등장한 수의 등장 횟수.
초기값으로 cnt = 0, mxval = -2^62-1, mxcnt = 0 을 주자.
이제 2부터 읽으면서 진행하자.


cnt 는 현재 보고 있는 수의 등장 횟수다.
현재 보고 있는 수가 제일 앞에 있는 수이거나 현재 보고 있는 수와 바로 직전에 나온 수가 같을 때에는 cnt 를 1 증가시키면 된다.
그래서 지금 '2'를 바라보고 있으니까 cnt를 1 증가 시키면 끝이다.
다음 숫자도 '2'니까 직전수와 똑같다. cnt를 1 증가시킨다.


다음 숫자도 '2'니까 cnt를 1 증가시킨다.
이제 '3'을 바라본다. 더이상 2가 연속하지 않는다.
이 때 mxval과 mxcnt를 업데이트해야 한다.
여태까지 가장 많이 등장한 횟수는 '2'가 '3'번 나온 것이다. mxval은 2로, mxcnt는 3으로 업데이트 하자.
'3'에 대한 개수를 세야 하니까 cnt=1로 변경해준다. 이제 3이 몇 개 있나 세면 된다.
// http://boj.kr/f3feaf22016f4c9687b84ab6be2f4389
#include <bits/stdc++.h>
using namespace std;
int n;
long long a[100005];
int main(void) {
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n;
for(int i = 0; i < n; i++)
cin >> a[i];
sort(a, a+n);
int cnt = 0;
long long mxval = -(1ll << 62) - 1; // 1을 long long으로 형변환하지 않고 1 << 62로 작성시 int overflow 발생
int mxcnt = 0;
for(int i = 0; i < n; i++){
if(i == 0 || a[i-1] == a[i]) cnt++; // i가 0인 경우 앞쪽 식이 true이기 때문에 a[i-1]을 참조하지 않음
else{
if(cnt > mxcnt){
mxcnt = cnt;
mxval = a[i-1];
}
cnt = 1;
}
}
if(cnt > mxcnt) mxval = a[n-1]; // 제일 마지막 수가 몇 번 등장했는지를 별도로 확인
cout << mxval;
}코드 마지막 줄에 '제일 마지막 수가 몇 번 등장했는지 별도로 확인'해야 한다.
이 처리가 빠지면 제일 마지막 수의 등장 횟수를 빠뜨리게 된다.
이 문제에서 사용한 정렬을 하면, 같은 수는 인접하게 된다는 성질을 이용해 수열에서 중복된 원소를 제거할 수 도 있다.
정렬2 문제집
문제를 풀 때는 퀵, 머지, 카운팅, 라딕스 소트를 직접 구현할 일은 없고 STL sort만 쓰겠지만, 이렇게 정리하고 나면 기술면접 대비에 도움이 된다.
특히 7795번 문제를 풀고, 다른 사람의 풀이를 찾아서 비교해보자.
다음 시간에는 다이나믹 프로그래밍을 배운다.
공부 내용 출처 : 바킹독 알고리즘 정렬2
'알고리즘 > 실전 알고리즘' 카테고리의 다른 글
| 0x10강 - 다이나믹 프로그래밍 (0) | 2021.12.19 |
|---|---|
| 0x0E강 - 정렬1 (0) | 2021.12.11 |
| 0x0C강 - 백트래킹 (0) | 2021.12.10 |
| 0x0B강 - 재귀 (0) | 2021.12.08 |
| 0x0A강 - DFS (0) | 2021.12.07 |