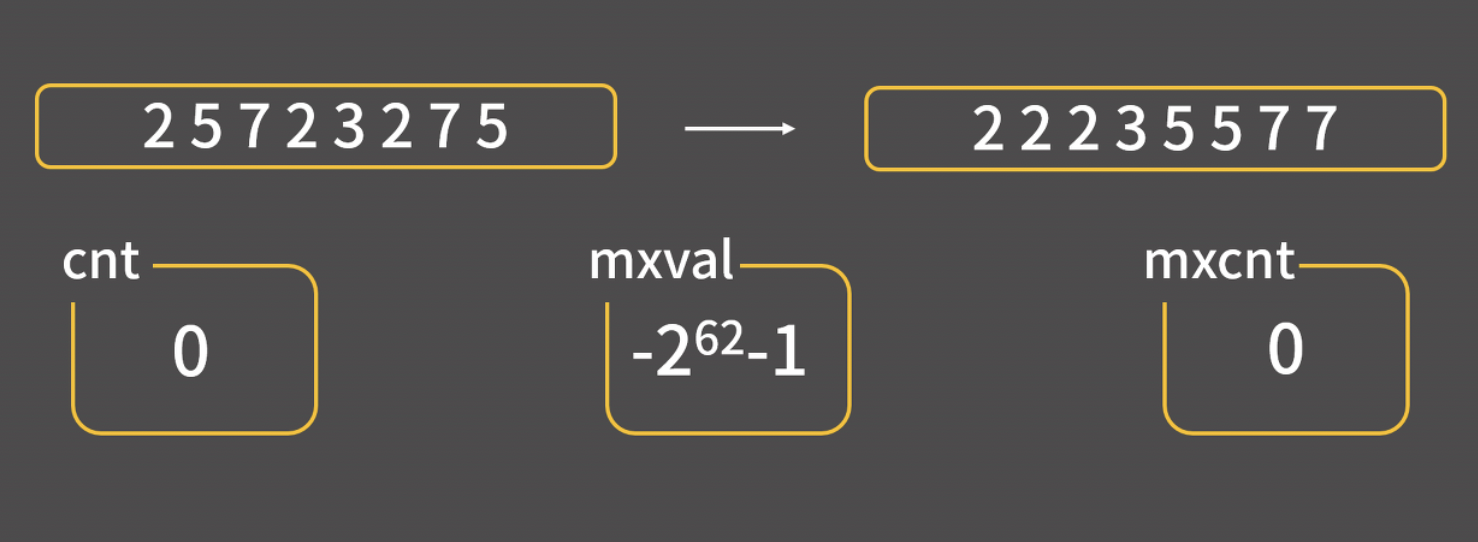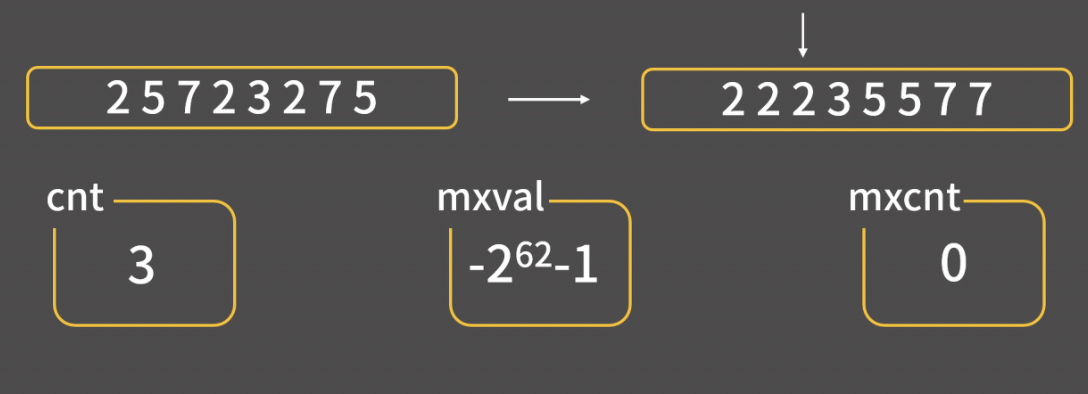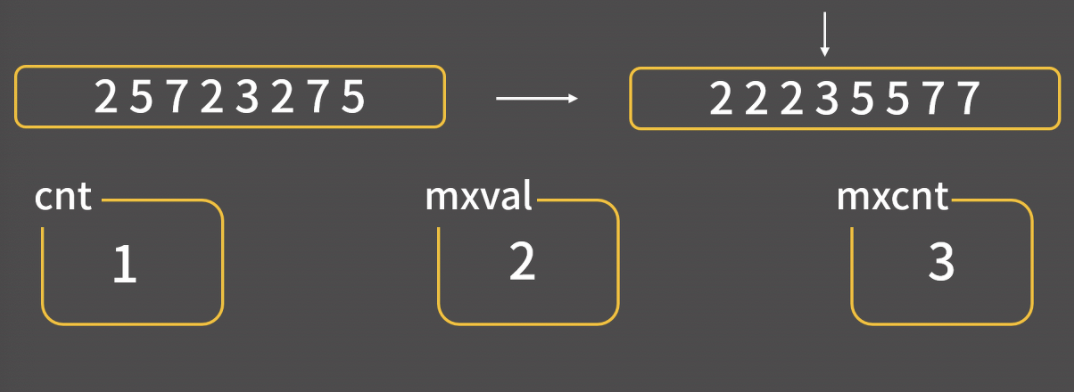#include<bits/stdc++.h>usingnamespacestd;
int n;
string st;
vector<string> v;
boolcmp(string &a, string & b){
if(a.size() != b.size()) return a.size() < b.size(); // 길이 짧은것 우선elsereturn a < b; // 사전순
}
intmain(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n;
for(int i = 0; i < n; i++) {
cin >> st;
v.push_back(st);
}
sort(v.begin(), v.end(), cmp);
v.erase(unique(v.begin(), v.end()), v.end());
for(auto i : v) cout << i << '\n';
return0;
}
리뷰
중복을 제거하는 것은 unique와 erase를 썼는데 이번에 풀면서 배웠다. unique 를 쓰면 중복은 제거되도 벡터의 크기가 줄어들지는 않는다. unique는 중복되는 원소의 포인터를 맨 뒤로 보내기 때문이다. unique의 리턴 값은 중복 제거 된 원소의 포인터다. 그래서 erase로 중복 제거된 원소의 포인터 부터 맨 마지막 포인터까지 공간을 삭제해준다. erase를 하면 아예 메모리가 해제되니까 중복된 부분의 크기만큼 반환되는 것이다.
#include<bits/stdc++.h>usingnamespacestd;
int n, num;
int arr[2000002];
intmain(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n;
for(int i = 1; i <= n; i++) {
cin >> num;
arr[num+1000000]++;
}
for(int i = 0; i <= 2000000; i++) {
while(arr[i] > 0) {
cout << i-1000000 << '\n';
arr[i]--;
}
}
return0;
}
리뷰
절대값이 100만 이하인 정수가 입력으로 들어오니까. 양수 음수 처리를 따로 해야겠다고 생각했었다. 일단 정답 코드를 제출하고 다른 분의 코드를 봤다. 200만 크기의 배열을 쓰면서도 어차피 입력받은 대로 더하고 빼주고 하면 입력 받은 숫자를 출력할 수 있으니까. 입력받을 때 저장하는 인덱스 : num + 1000000 출력할 때 숫자 : num - 1000000 이렇게 하면 충분했다.
두 원소의 우선순위가 같다면 원소의 위치를 변경하지 않는다. 사용법은 sort()와 똑같다.
[중요] 비교 함수
sort() 함수의 파라미터로 비교함수를 넘길 수 있다. stable_sort()도 마찬가지다.
예를 들어, int형을 5로 나눈 나머지 순으로, 5로 나눈 나머지가 같다면 크기 순으로 정렬하고 싶으면 아래 코드처럼 하면 된다.
비교함수 cmp는 a가 b의 앞에 와야할 때 true를, 그렇지 않을 때 false를 반환한다.
boolcmp(int a, int b){ // a가 b의 앞에 와야할 때 true, 아니면 false if(a % 5 != b % 5) return a % 5 < b % 5;
else a < b;
}
int a[7] = {1, 2, 3, 4, 5, 6, 7};
sort(a, a+7, cmp);
// 출력 결과: 5 1 6 2 7 3 4
비교함수 구현 시 자주하는 실수
1. a가 b의 앞에 와야할 때만 true를 반환한다. a==b 라면 false를 반환한다.
예를 들어, 수열을 크기의 내림차순으로 정렬하고 싶을 때, a와 b가 같은 경우 false를 반환하니까 런타임 에러가 발생할 수 있다.
boolcmp(int a, int b){ // [런타임 에러 발생]if(a >= b) returntrue;
returnfalse;
}
a > b 일 때 true를 반환하도록 수정하자.
boolcmp(int a, int b){ // 올바른 형태return a > b;
}
2. 비교 함수의 인자로 STL 혹은 클래스 객체를 전달시 reference를 사용하자.
문자열을 받아서 끝자리의 알파벳 순으로 정렬하고 싶어서 비교함수를 작성했다.
아래의 비교함수는 어떻게 개선하면 좋을까?
boolcmp(string a, string b){
return a.back() < b.back();
}
// 함수의 인자로 STL이나 구조체 객체를 보내면 값의 '복사'가 일어난다!
함수의 인자로 STL이나 구조체 객체를 보내면 값의 '복사'가 일어남을 기억하자!
이 경우, 굳이 복사라는 불필요한 연산이 없어도 비교가 가능하다.
따라서 복사를 하는 대신 아래처럼 reference를 보내는 것이 더 바람직하다.
boolcmp(const string& a, const string& b){ // 레퍼런스를 보내서 비교하는 것이 효율적.return a.back() < b.back();
}
const string& a, const string& b라고 쓰면 a와 b는 변하지 않음을 명시적으로 나타내기 때문에 가독성이 도움이 된다.
#include<bits/stdc++.h>usingnamespacestd;
int n, num;
int arr[10001];
intmain(void){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n;
for(int i = 0; i < n; i++){
cin >> num; arr[num]++;
}
for(int i = 1; i <= 10000; i++){
while(arr[i]){
cout << i << '\n'; arr[i]--;
}
}
return0;
}
리뷰
이 문제는 sort() 함수를 쓰면 틀린다. 왜냐하면 메모리 제한이 8MB 이다. int 는 4bytes니까. 문제 조건인 천 만개 배열을 선언하면 40MB 를 차지한다. 10000 보다 작은 자연수만 입력으로 들어오니까, 10000을 배열의 인덱스로 두고. 인덱스에 해당하는 숫자의 '개수'를 배열의 값으로 저장해서 해결하면 된다.
그 다음 큰 것을 찾아서 뒤로 보낸다 ... 이렇게 이어질 테니 계산해보면 시간복잡도는 O(N^2) 이다.
선택정렬 코드
int arr[10] = {3, 2, 7, 116, 62, 235, 1, 23, 55, 77};
int n = 10;
for(int i = n-1; i > 0; i--){ // 최대값을 찾으면 i위치로 보낼것이다. i:맨 마지막부터 앞에서 두번째 까지.int mxidx = 0;
for(int j = 1; j <= i; j++){
if(arr[mxidx] < arr[j]) mxidx = j;
}
swap(arr[mxidx], arr[i]);
}
선택 정렬은 가장 큰 수를 찾으면, 인덱스 i로 이동시킨다. 내부 반복문에서 mxidx 인덱스와 j인덱스 자리의 숫자를 비교한다. 이 반복문이 종료되면 가장 큰 숫자의 인덱스가 mxidx에 저장된다. 가장 큰 숫자 인덱스 mxidx와 뒤쪽 인덱스 i를 swap한다. ( == 가장 큰 숫자를 뒤로 보낸다)
max_element 함수로 줄여본 코드
max_element(arr, arr+k)
// arr[0], arr[1], arr[2], .. , arr[k-1] 에서 최댓값인 원소의 주소를 반환
arr[0]부터 arr[k-1] 까지 탐색한 후 최댓값인 원소 주소를 반환한다.
arr[k]가 아니라 arr[k-1]임을 주의하자.
int arr[10] = {3, 2, 7, 116, 62, 235, 1, 23, 55, 77};
int n = 10;
for(int i = n-1; i > 0; i--){ // 맨 마지막부터 앞에서 두번째 까지.swap(*max_element(arr, arr+i+1), arr[i]);
}