목차
0x00 수식의 괄호 쌍이란?
0x01 문제 해결을 위한 관찰
0x02 문제 해결 방법
0x03 연습문제
0x00 수식의 괄호 쌍이란?
수식의 괄호 쌍이 짝이 맞는지 확인해보자.
( 이 있으면 ) 으로 닫아야 짝이 맞다. { 이 있으면 } 이 있어야한다.

두 번째 식에서 (12+4} 여기가 틀렸다. 이와 같이 수식의 괄호 쌍이란, 주어진 괄호 문자열이 올바른지 판단하는 문제다.
0x01 문제 해결을 위한 관찰
아래의 3개 수식 중에 올바른 괄호 쌍은 무엇 무엇이 있을까?

결론부터 말하면 첫 번째 식만 올바른 괄호 쌍이다.
판단 방법 중에 가장 보편적인 방법은 바로 안쪽부터 짝 맞추기를 해서 지워나가는 방법이다.
그리고 관찰력이 뛰어나다면, ')' 의 개수가 '(' 의 갯수를 넘지 않으면 된다는 사실도 있다.
괄호의 종류가 () 말고도 {}, [] 이 있다면, 여는 괄호의 갯수와 닫는 괄호의 갯수 비교만으로 해결되지 않는다.
우리는 머릿속으로 어떤 로직을 거쳐서 판단한 걸까? 생각의 과정을 관찰하여 코드로 구현해보자.
스택을 이용하여 구현해보자.
아래의 관찰을 인지해야 한다.
"닫는 괄호는 남아있는 괄호 중에서
가장 최근에 읽은 여는 괄호와 짝을 지어 없애버리는 명령이다. "

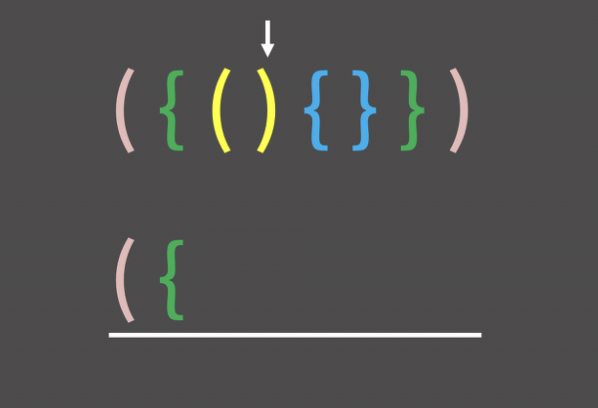
1. 스택을 하나 두고, 문자열을 읽어 나가다가 여는 괄호를 만나면 모두 스택에 넣는다.
2. 문자열을 읽어 나가다가 닫는 괄호를 만나면 스택의 top을 확인한다.
3. 지금 읽은 것이 닫는 괄호이고 스택의 top이 여는괄호라면? 쌍이 올바른 것이다.
4. 따라서 스택의 top인 여는 괄호를 스택에서 지운다. pop()
올바르지 않은 괄호 쌍
올바르지 않은 괄호 쌍의 경우, 과정을 살펴보자.


1. 문자열을 읽다가 만난 여는 괄호 2개는 모두 스택에 넣는다.
2. 닫는 괄호 ) 를 만나면, 스택의 top을 확인한다.
현재 스택의 top은 { 이다.
3. 스택의 top인 {와 닫는괄호 ) 는 짝이 안맞는다.
올바르지 않은 괄호 쌍의 예시 2가지


1. 문자열을 끝까지 읽었는데, 스택에 여는 괄호가 남아있다.
2. 문자열을 끝까지 읽고 스택도 비었는데, 닫는 괄호가 남아있다.
0x02 문제 해결 방법
올바른 괄호 쌍 판단을 위해 문제 해결 방법을 정리해본다.
1. 여는 괄호가 나오면 스택에 추가.
2. 닫는 괄호가 나왔을 경우, 스택의 top이 짝이 맞는 괄호라면 pop
3. 스택에 괄호가 남아있지 않으면 올바른 괄호 쌍.

스택이 비었을 때 top을 참조하면 런타임에러!
0x03 연습문제
수식의 괄호쌍이 코딩테스트에서 무조건 나온다고 할 정도로 중요하진 않지만,
stack을 이용한 문제가 많기 때문에 연습문제를 꼭 풀어보자.
| 백준 문제 | 내 코드 |
| 4949번 균형잡힌 세상 | 균형잡힌 세상 내 코드 |
| 3986번 좋은 단어 | 좋은 단어 내 코드 |
| 9012번 괄호 | |
| 10799번 쇠막대기 | |
| 2504 괄호의 값 | 괄호의 값 내 코드 |
다음 시간에는 BFS를 배운다.
공부 자료 출처 : 바킹독 알고리즘 수식의 괄호 쌍
'알고리즘 > 실전 알고리즘' 카테고리의 다른 글
| 0x0A강 - DFS (0) | 2021.12.07 |
|---|---|
| 0x09강 - BFS (0) | 2021.12.07 |
| 0x07강 - 덱 (0) | 2021.11.24 |
| 0x06강 - 큐 (0) | 2021.11.23 |
| 0x05강 - 스택 (0) | 2021.11.23 |